
技術資料・ベストプラクティス
運用上のベストプラクティス
データストアとプロトコル
データストアとボリュームのプロビジョニングには、可能であれば必ずONTAPツールを使用してください。これにより、ボリューム、ジャンクションパス、LUN、igroup、エクスポートポリシー およびその他の設定は互換性のある方法で構成されています。
SRMは、SRAを介したアレイベースのレプリケーションを使用する場合、ONTAP 9でiSCSI、ファイバチャネル、NFSバージョン3をサポートします。SRMは、従来のデータストアまたはvVolデータストアを使用したNFSバージョン4.1のアレイベースのレプリケーションをサポートしていません。
接続を確認するには、必ず、DRサイトの新しいテスト用データストアをデスティネーションONTAPクラスタからマウントおよびアンマウントできることを確認してください。データストアの接続に使用する各プロトコルをテストします。SRMの指示に従ってデータストアの自動化がすべて実行されるため、ONTAPツールを使用してテスト用データストアを作成することを推奨します。
SANプロトコルはサイトごとに同機種である必要があります。NFSとSANを混在させることはできますが、サイト内でSANプロトコルを混在させることはできません。たとえば、サイトAでFCPを使用すると、 サイトBでは、FCPとiSCSIの両方をサイトAで使用しないでください。これは、SRAがリカバリーサイトに混在したigroupを作成せず、SRAに指定されたイニシエータリストがフィルタリングされないためです。
可能なかぎり、クラスタを対象としたクレデンシャルを指定した場合でも、ONTAPツールではデータに対してローカルなLIF間で負荷を分散するように選択されますが、高可用性やパフォーマンスを確保するための必須要件ではありません。
ONTAP 9では、autosizeコマンドで緊急時に十分な容量を確保できない場合に、スペース不足が発生したときにアップタイムを維持するためにSnapshotコピーを自動的に削除するように設定できます。この機能のデフォルト設定では、SnapMirrorで作成されたSnapshotコピーは自動的に削除されません。SnapMirror Snapshotコピーが削除されると、SRAは影響を受けたボリュームのレプリケーションを反転および再同期できません。ONTAPでSnapMirror Snapshotコピーが削除されないようにするには、Snapshot自動削除機能をtryに設定します。
snap autodelete modify –volume -commitment try
ボリュームのオートサイズは grow 、SANデータストアを含むボリュームの場合はに設定し、 grow_shrink NFSデータストアの場合はに設定する必要があります。特定の構文については、ONTAP 9コマンドリファレンスと https://storage-system.fujitsu.com/manual/ja/axhx/#tab-d-02 を参照してください。
SPBMとVVOL
SRM 8.3以降では、vVolデータストアを使用したVMの保護がサポートされています。次のスクリーンショットに示すように、ONTAP toolsの設定メニューでvVolレプリケーションが有効になっている場合、SnapMirrorスケジュールはVASA ProviderによってVMストレージポリシーに公開されます。
次の例は、vVolレプリケーションを有効にする方法を示しています。
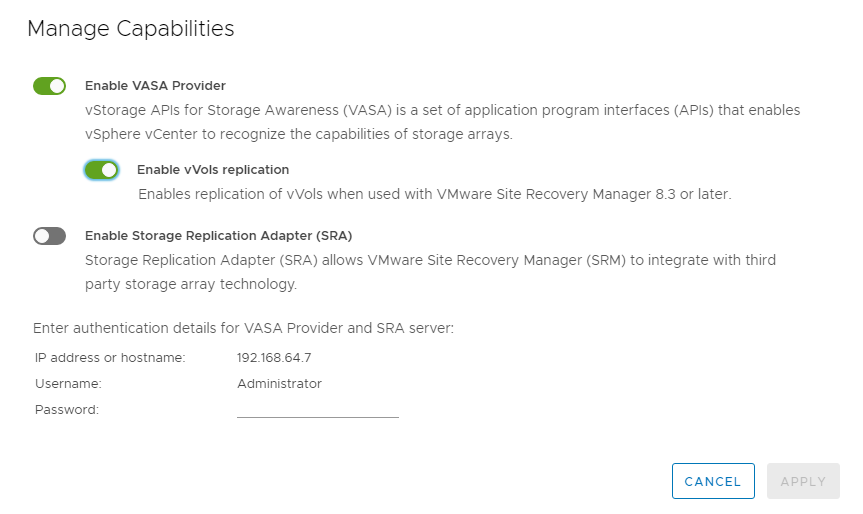
次のスクリーンショットは、Create VM Storage Policyウィザードに表示されるSnapMirrorスケジュールの例を示しています。
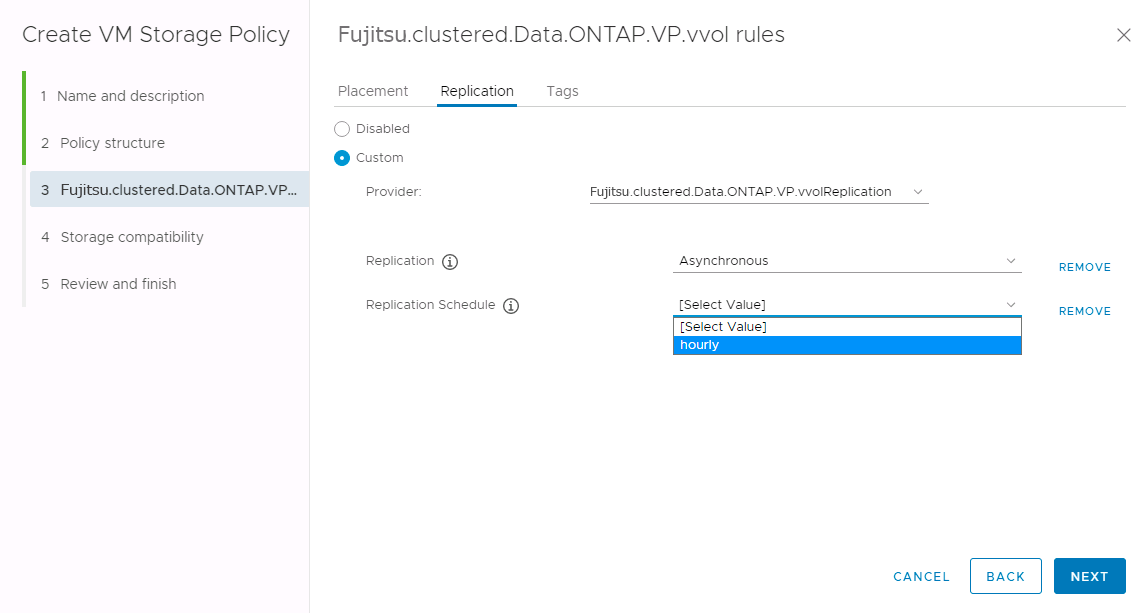
ONTAP VASA Providerでは、異なるストレージへのフェイルオーバーがサポートされます。
ストレージの類似性に関係なく、レプリケーションに対応したVMストレージポリシーのストレージポリシーマッピングとリバースマッピングを常に設定して、リカバリーサイトで提供されるサービスが期待と要件を満たしていることを確認する必要があります。次のスクリーンショットは、サンプルのポリシーマッピングを示しています。
vVolデータストア用のレプリケートされたボリュームを作成する
以前のvVolデータストアとは異なり、レプリケートされたvVolデータストアは、最初からレプリケーションを有効にして作成する必要があります。また、SnapMirror関係が確立されたONTAPシステムで事前に作成されたボリュームを使用する必要があります。そのためには、クラスタピアリングやSVMピアリングなどを事前に設定する必要があります。これらのアクティビティはONTAP管理者が実行する必要があります。これにより、複数のサイトでONTAPシステムを管理する担当者とvSphereの運用を主に担当する担当者が厳密に分離されます。
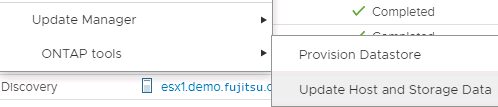
これには、vSphere管理者の代わりに新たな要件があります。ボリュームはONTAPツールの範囲外で作成されるため、定期的にスケジュールされた再検出期間までは、ONTAP管理者が行った変更は認識されません。そのため、VVOLで使用するボリューム関係またはSnapMirror関係を作成するときは、必ず再検出を実行することを推奨します。次のスクリーンショットに示すように、ホストまたはクラスタを右クリックし、 [ONTAP tools]>[Update Host and Storage Data]を選択します。
VVOLとSRMについては、注意が必要です。保護されているVMと保護されていないVMを同じvVolデータストアに混在させないでください。これは、SRMを使用してDRサイトにフェイルオーバーする場合、保護グループに含まれるVMだけがDRでオンラインになるためです。そのため、再保護(SnapMirrorをDRから本番環境に反転)すると、フェイルオーバーされておらず貴重なデータが含まれていたVMが上書きされる可能性があります。
アレイペアについて
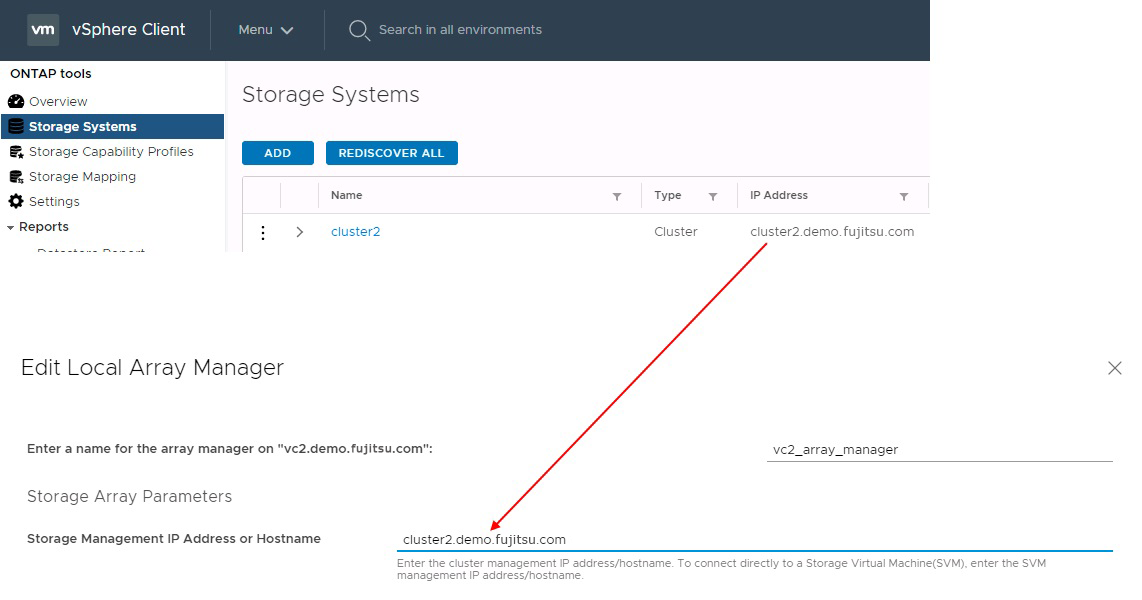
アレイペアごとにアレイ・マネージャが作成されますSRMツールとONTAPツールでは、クラスタのクレデンシャルを使用している場合でも、各アレイはSVMスコープでペアリングされます。これにより、管理対象として割り当てられたSVMに基づいて、テナント間でDRワークフローをセグメント化できます。特定のクラスタに対して複数のアレイマネージャを作成できますが、これらは非対称にすることができます。異なるONTAP 9クラスタ間では、ファンアウトまたはファンインが可能です。たとえば、クラスタ1のSVM-AとSVM-Bを、クラスタ2のSVM-C、クラスタ3のSVM-D、またはその逆にレプリケートできます。
SRMでアレイペアを設定する場合は、ONTAPツールに追加したのと同じ方法で必ずSRMに追加してください。つまり、同じユーザー名、パスワード、および管理LIFを使用する必要があります。この要件により、SRAはアレイと適切に通信します。次のスクリーンショットは、クラスタがONTAPツールに表示される仕組みとアレイマネージャに追加される仕組みを示しています。
レプリケーショングループについて
レプリケーショングループには、一緒にリカバリーされる仮想マシンの論理コレクションが含まれます。ONTAP tools VASA Providerを使用すると、レプリケーショングループが自動的に作成されます。ONTAP SnapMirrorレプリケーションはボリュームレベルで実行されるため、ボリューム内のすべてのVMは同じレプリケーショングループに属します。
レプリケーショングループと、FlexVolボリューム間でVMを分散する方法については、いくつかの考慮事項があります。類似するVMを同じボリュームにグループ化すると、アグリゲートレベルの重複排除機能がない古いONTAPシステムでストレージ効率を高めることができますが、グループ化するとボリュームのサイズが大きくなり、ボリュームのI/Oの同時実行数が少なくなります。最新のONTAPシステムでは、同じアグリゲート内のFlexVolボリュームにVMを分散することで、パフォーマンスとストレージ効率の最適なバランスを実現できます。その結果、アグリゲートレベルの重複排除が活用され、複数のボリューム間でI/Oの並列化が促進されます。保護グループ(後述)に複数のレプリケーショングループを含めることができるため、ボリューム内のVMをまとめてリカバリーできます。このレイアウトの欠点は、Volume SnapMirrorではアグリゲートの重複排除が考慮されないため、ブロックがネットワーク経由で複数回送信される可能性があることです。
レプリケーショングループの最後の考慮事項の1つは、それぞれが本質的に論理整合グループであることです(SRMコンシステンシグループと混同しないでください)。これは、ボリューム内のすべてのVMが同じSnapshotを使用して一緒に転送されるためです。したがって、相互に整合性が必要なVMがある場合は、それらを同じFlexVolに格納することを検討してください。
保護グループについて
保護グループは、保護サイトからまとめてリカバリーされるVMとデータストアをグループに定義します。保護サイトとは、保護グループに設定されているVMが、通常の安定した運用中に存在するサイトです。SRMでは、1つの保護グループに対して複数のアレイマネージャが表示される場合がありますが、1つの保護グループが複数のアレイマネージャにまたがることはできません。そのため、異なるSVM上のデータストアにまたがるVMファイルは使用しないでください。
リカバリープランについて
リカバリープランでは、同じプロセスでリカバリーする保護グループを定義します。同じリカバリープランで複数の保護グループを設定できます。また、リカバリープランの実行オプションを増やすために、1つの保護グループを複数のリカバリープランに含めることもできます。
リカバリープランでは、SRM管理者がリカバリーワークフローを定義するために、VMを1(最高)から5(最低)の優先度グループに割り当てます。デフォルトは3(中)です。優先度グループ内で、VMに依存関係を設定できます。
たとえば、データベースにMicrosoft SQL Serverを使用するティア1のビジネスクリティカルなアプリケーションがあるとします。そのため、優先度グループ1にVMを配置します。優先度グループ1内で、サービスを起動する順序の計画を開始します。Microsoft SQL Serverがアプリケーションサーバーの前にオンラインである必要がある場合など、Microsoft Windowsドメインコントローラーを起動する前に起動する必要があります。依存関係は特定の優先度グループ内でのみ適用されるため、これらすべてのVMを優先度グループに追加してから依存関係を設定します。
テストフェイルオーバー
ベストプラクティスとして、保護対象のVMストレージの構成に変更が加えられた場合は、必ずテストフェイルオーバーを実行することを推奨します。これにより、災害発生時にSite Recovery Managerが予想されるRTOターゲット内でサービスをリストアできると信頼できます。
特にVMストレージの再構成後に、ゲスト内アプリケーションの機能を確認することも推奨しています。
テストリカバリー処理を実行すると、VM用のESXiホストにプライベートテストバブルネットワークが作成されます。ただし、このネットワークは物理ネットワークアダプターに自動的に接続されないため、ESXiホスト間の接続は提供されません。DRテスト中に異なるESXiホストで実行されているVM間の通信を可能にするために、DRサイトのESXiホスト間に物理的なプライベートネットワークが作成されます。テスト用ネットワークがプライベートであることを確認するには、テスト用バブルネットワークを物理的に分離するか、VLANまたはVLANタギングを使用して分離します。VMのリカバリー時に、実際の本番システムと競合する可能性のあるIPアドレスを使用して本番ネットワークにVMを配置することはできないため、このネットワークは本番ネットワークから分離する必要があります。SRMでリカバリープランを作成すると、作成したテストネットワークを、テスト中にVMを接続するプライベートネットワークとして選択できます。
テストが検証され、不要になったら、クリーンアップ処理を実行します。クリーンアップを実行すると、保護対象のVMが初期状態に戻り、リカバリープランがReady状態にリセットされます。
フェイルオーバーに関する考慮事項
サイトのフェイルオーバーに関しては、このガイドで説明する処理の順序以外にも、いくつかの考慮事項があります。
競合しなければならない可能性のある1つの問題は、サイト間のネットワークの違いです。環境によっては、プライマリーサイトとDRサイトの両方で同じネットワークIPアドレスを使用できます。この機能は、拡張仮想LAN(VLAN)または拡張ネットワークセットアップと呼ばれます。それ以外の環境では、プライマリーサイトでDRサイトとは異なるネットワークIPアドレス(異なるVLANなど)を使用しなければならない場合があります。
VMwareでは、この問題を解決する方法をいくつか提供しています。たとえば、VMware NSX-T Data Centerなどのネットワーク仮想化テクノロジは、運用環境のレイヤー2からレイヤー7までのネットワークスタック全体を抽象化し、より移植性の高いソリューションを実現します。SRMでのNSX-Tオプションの詳細 については、こちらをご覧ください。
SRMでは、リカバリー時にVMのネットワーク構成を変更することもできます。この再設定には、IPアドレス、ゲートウェイアドレス、DNSサーバー設定などの設定が含まれます。リカバリー時に個 々 のVMに適用されるさまざまなネットワーク設定は、リカバリープランのVMのプロパティ設定で指定できます。
VMwareでは、リカバリープラン内の各VMのプロパティを編集することなく、SRMが複数のVMに異なるネットワーク設定を適用するように設定できるように、dr-ip-customizerというツールを提供しています。このユーティリティーの使用方法については 、VMwareのドキュメントを参照してください。
再保護
リカバリー後、リカバリーサイトが新しい本番サイトになります。リカバリー処理によってSnapMirrorレプリケーションが中断されたため、新しい業務用サイトは将来の災害から保護されません。リカバリー後すぐに新しい本番サイトを別のサイトに保護することを推奨します。元の本番サイトが稼働している場合、VMware管理者は元の本番サイトを新しいリカバリーサイトとして使用して新しい本番サイトを保護し、保護の方向を効果的に反転させることができます。再保護は、致命的でない障害でのみ使用できます。そのため、元のvCenter Server、ESXiサーバー、SRMサーバー、および対応するデータベースを最終的にリカバリーできる必要があります。使用できない場合は、新しい保護グループと新しいリカバリープランを作成する必要があります。
フェイルバック
フェイルバック操作は、基本的に、以前とは異なる方向へのフェールオーバーです。ベストプラクティスとして、フェイルバック(つまり、元のサイトへのフェイルオーバー)を試行する前に、元のサイトが許容可能なレベルの機能に戻っていることを確認することを推奨します。元のサイトが引き続き侵害されている場合は、障害が十分に修復されるまでフェイルバックを遅らせる必要があります。
フェイルバックのもう1つのベストプラクティスは、再保護が完了したあと、最終的なフェイルバックを実行する前に、常にテストフェイルオーバーを実行することです。これにより、元のサイトに設置されているシステムが処理を完了できることが確認されます。
元のサイトを再保護します
フェイルバック後、再保護を再度実行する前に、すべてのステークホルダーに対してサービスが正常に戻ったことを確認する必要があります。
フェイルバック後に再保護を実行すると、基本的に環境は当初の状態に戻り、業務用サイトからリカバリーサイトにSnapMirrorレプリケーションが再度実行されます。