
![]()
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
MetroCluster マニュアル ( CA08871-401 )
クラスタをMetroCluster構成に設定
クラスタをピアリングし、ルート アグリゲートをミラーリングし、ミラーリングされたデータ アグリゲートを作成し、コマンドを実行してMetroClusterの処理を実装する必要があります。
metrocluster configureを実行するまで、HAモードとDRミラーリングは有効になっておらず、この想定される動作に関連してエラーが表示されることがあります。HAモードとDRミラーリングは、あとで構成を導入するためにmetrocluster configureコマンドを実行する際に有効にします。
クラスタのピアリング
MetroCluster構成内のクラスタが相互に通信し、MetroClusterディザスタ リカバリーに不可欠なデータ ミラーリングを実行できるようにするために、クラスタ間にはピア関係が必要です。
クラスタ ピアリング用のクラスタ間LIFの設定
MetroClusterパートナー クラスタ間の通信に使用するポートにクラスタ間LIFを作成する必要があります。専用のポートを使用することも、データ トラフィック用を兼ねたポートを使用することもできます。
専用ポートでのクラスタ間LIFの設定
専用ポートにクラスタ間LIFを設定できます。通常は、この設定により、レプリケーション トラフィックに使用可能な帯域幅が拡張します。
-
クラスタ内のポートの一覧を表示します。
network port showコマンド構文全体については、マニュアル ページを参照してください。
次の例は、「cluster01」内のネットワーク ポートを示しています。
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
クラスタ間通信専用として使用可能なポートを決定します。
network interface show -fields home-port,curr-portコマンド構文全体については、マニュアル ページを参照してください。
次の例は、ポート「e0e」とポート「e0f」にLIFが割り当てられていないことを示しています。
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
専用ポートのフェイルオーバー グループを作成します。
network interface failover-groups create -vserver system_SVM -failover-group failover_group -targets physical_or_logical_ports次の例は、ポート「e0e」とポート「e0f」を、システム「SVMcluster01」上のフェイルオーバー グループ「intercluster01」に割り当てます。
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
フェイルオーバー グループが作成されたことを確認します。
network interface failover-groups showコマンド構文全体については、マニュアル ページを参照してください。
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
システムSVMにクラスタ間LIFを作成して、フェイルオーバー グループに割り当てます。
ONTAPバージョン
コマンド
9.7以降
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupコマンド構文全体については、マニュアル ページを参照してください。
次の例は、フェイルオーバー グループ「intercluster01」にクラスタ間LIF「cluster01_icl01」と「cluster01_icl02」を作成します。
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
クラスタ間LIFが作成されたことを確認します。
ONTAP 9.7以降:
network interface show -service-policy default-interclusterコマンド構文全体については、マニュアル ページを参照してください。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
クラスタ間LIFが冗長構成になっていることを確認します。
ONTAP 9.7以降
network interface show -service-policy default-intercluster -failoverコマンド構文全体については、マニュアル ページを参照してください。
次の例は、「e0e」ポート上のクラスタ間LIF「cluster01_icl01」と「cluster01_icl02」が「e0f」ポートにフェイルオーバーされることを示しています。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
共有データ ポートでのクラスタ間LIFの設定
データ ネットワークと共有するポートにクラスタ間LIFを設定できます。これにより、クラスタ間ネットワークに必要なポート数を減らすことができます。
-
クラスタ内のポートの一覧を表示します。
network port showコマンド構文全体については、マニュアル ページを参照してください。
次の例は、「cluster01」内のネットワーク ポートを示しています。
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
システムSVMにクラスタ間LIFを作成します。
ONTAP 9.7以降
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskコマンド構文全体については、マニュアル ページを参照してください。
次の例は、クラスタ間LIF「cluster01_icl01」と「cluster01_icl02」を作成します。
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
クラスタ間LIFが作成されたことを確認します。
ONTAP 9.7以降
network interface show -service-policy default-interclusterコマンド構文全体については、マニュアル ページを参照してください。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
クラスタ間LIFが冗長構成になっていることを確認します。
ONTAP 9.7以降
network interface show –service-policy default-intercluster -failoverコマンド構文全体については、マニュアル ページを参照してください。
次の例は、「e0c」ポート上のクラスタ間LIF「cluster01_icl01」と「cluster01_icl02」が「e0d」ポートにフェイルオーバーされることを示しています。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
クラスタ ピア関係の作成
cluster peer createコマンドを使用すると、ローカル クラスタとリモート クラスタ間にピア関係を作成できます。ピア関係が作成されたあとで、cluster peer createをリモート クラスタで実行して、ローカル クラスタに対してピア関係を認証できます。
-
ピア関係にあるクラスタ内の各ノードでクラスタ間LIFを作成しておく必要があります。
-
デスティネーション クラスタで、ソース クラスタとのピア関係を作成します。
cluster peer create -generate-passphrase -offer-expiration MM/DD/YYYY HH:MM:SS|1…7days|1…168hours -peer-addrs peer_LIF_IPs -ipspace ipspace-generate-passphraseと-peer-addrsの両方を指定した場合、生成されたパスワードを使用できるのは-peer-addrsにクラスタ間LIFが指定されたクラスタのみになります。カスタムIPspaceを使用しない場合は、
-ipspaceオプションを無視してかまいません。コマンド構文全体については、マニュアル ページを参照してください。次の例は、リモート クラスタを指定せずにクラスタ ピア関係を作成します。
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
ソース クラスタで、ソース クラスタをデスティネーション クラスタに対して認証します。
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceコマンド構文全体については、マニュアル ページを参照してください。
次の例は、クラスタ間LIFのIPアドレス「192.140.112.101」および「192.140.112.102」でローカル クラスタをリモート クラスタに対して認証します。
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.プロンプトが表示されたら、ピア関係のパスフレーズを入力します。
-
クラスタ ピア関係が作成されたことを確認します。
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
ピア関係にあるノードの接続状態とステータスを確認します。
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
DRグループの作成
クラスタ間にディザスタ リカバリー(DR)グループ関係を作成する必要があります。
この手順は、MetroCluster構成のどちらかのクラスタで実行します。一方のクラスタで実行すると、両方のクラスタのノード間にDR関係が作成されます。
|
Note
|
DRグループを作成したあとにDR関係を変更することはできません。 |
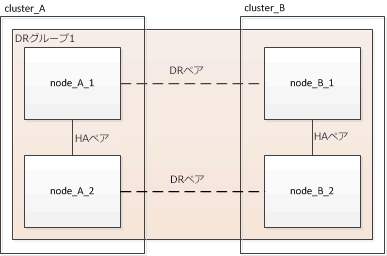
-
各ノードで次のコマンドを入力して、DRグループを作成する準備ができていることを確認します。
metrocluster configuration-settings show-statusコマンドの出力に、ノードの準備が完了していることが示されます。
cluster_A::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_A node_A_1 ready for DR group create node_A_2 ready for DR group create 2 entries were displayed.cluster_B::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_B node_B_1 ready for DR group create node_B_2 ready for DR group create 2 entries were displayed. -
DRグループを作成します。
metrocluster configuration-settings dr-group create -partner-cluster partner-cluster-name -local-node local-node-name -remote-node remote-node-nameこのコマンドは1回だけ実行します。パートナー クラスタで繰り返す必要はありません。このコマンドでは、リモート クラスタの名前、および1つのローカル ノードとパートナー クラスタの1つのノードの名前を指定します。
指定した2つのノードがDRパートナーとして設定され、他の2つのノード(コマンドで指定していないノード)がDRグループの2つ目のDRペアとして設定されます。このコマンドの入力後にこれらの関係を変更することはできません。
次のコマンドでは、次のDRペアが作成されます。
-
node_A_1とnode_B_1
-
node_A_2とnode_B_2
Cluster_A::> metrocluster configuration-settings dr-group create -partner-cluster cluster_B -local-node node_A_1 -remote-node node_B_1 [Job 27] Job succeeded: DR Group Create is successful.
-
MetroCluster IPインターフェイスの設定と接続
各ノードのストレージと不揮発性キャッシュのレプリケーションに使用するMetroCluster IPインターフェイスを設定する必要があります。その後、設定したMetroCluster IPインターフェイスを使用して接続を確立します。これにより、ストレージ レプリケーション用のiSCSI接続が作成されます。
|
Note
|
MetroClusterのIPアドレスは初期設定後は変更できないため、慎重に選択する必要があります。 |
-
ノードごとに2つのインターフェイスを作成する必要があります。インターフェイスはMetroClusterのRCFファイルで定義されているVLANに関連付ける必要があります。
-
MetroCluster IPインターフェイス「A」のすべてのポートを同じVLANに作成し、MetroCluster IPインターフェイス「B」のすべてのポートをもう一方のVLANに作成する必要があります。 「MetroCluster IP構成に関する考慮事項」を参照してください。
Note-
一部のプラットフォームでは、MetroCluster IPインターフェイスにVLANが使用されます。デフォルトでは、2つのポートのそれぞれで異なるVLAN(10と20)が使用されます。
metrocluster configuration-settings interface createコマンドの-vlan-idパラメーターを使用して、デフォルトとは異なる100よりも大きいVLAN(101~4095)を指定することもできます。 -
ONTAP 9.9.1以降では、レイヤー3構成を使用している場合、MetroCluster IPインターフェイスの作成時に
-gatewayパラメーターも指定する必要があります。「レイヤー3ワイドエリア ネットワークに関する考慮事項」を参照してください。
使用されているVLANが10と20、または100よりも大きい場合、次のプラットフォーム モデルを既存のMetroCluster構成に追加できます。他のVLANが使用されている場合は、これらのプラットフォームを既存の構成に追加することはできません。MetroClusterインターフェイスを設定できないためです。 他のプラットフォームを使用している場合、ONTAPでは必要ないため、VLAN構成は問題になりません。
ETERNUS AX series
ETERNUS HX series
-
ETERNUS AX2100
-
ETERNUS AX2200
-
ETERNUS AX4100
-
ETERNUS HX2200
-
ETERNUS HX6100
この例では、次のIPアドレスとサブネットを使用しています。
ノード
インターフェイス
IPアドレス
サブネット
node_A_1
MetroCluster IPインターフェイス1
10.1.1.1
10.1.1/24
MetroCluster IPインターフェイス2
10.1.2.1
10.1.2/24
node_A_2
MetroCluster IPインターフェイス1
10.1.1.2
10.1.1/24
MetroCluster IPインターフェイス2
10.1.2.2
10.1.2/24
node_B_1
MetroCluster IPインターフェイス1
10.1.1.3
10.1.1/24
MetroCluster IPインターフェイス2
10.1.2.3
10.1.2/24
node_B_2
MetroCluster IPインターフェイス1
10.1.1.4
10.1.1/24
MetroCluster IPインターフェイス2
10.1.2.4
10.1.2/24
次の表に示すように、MetroCluster IPインターフェイスで使用される物理ポートはプラットフォーム モデルによって異なります。
プラットフォーム モデル MetroCluster IPポート メモ ETERNUS AX4100
e1a
e1b
ETERNUS AX4100およびETERNUS HX6100
e1a
e1b
ETERNUS AX2100およびETERNUS HX2200
e0a
これらのシステムでは、これらの物理ポートがクラスタ インターフェイスとしても使用されます。
e0b
ETERNUS AX2200
e0c
e0d
ETERNUS HX6100
e1a
e1b
-
プール1のドライブ割り当ての確認または手動実行
ストレージ構成に応じて、プール1のドライブ割り当てを確認するか、MetroCluster IP構成の各ノードのプール1に手動でドライブを割り当てる必要があります。使用する手順は、使用しているONTAPのバージョンによって異なります。
構成タイプ |
操作手順 |
|---|---|
このシリーズは、自動ドライブ割り当ての要件を満たしています。 |
|
構成には3つのシェルフが含まれるか、または4つを超えるシェルフが含まれる場合は、4シェルフの不均等な倍数(例えば、7つのシェルフ)が含まれます。 |
|
この構成には、サイトごとに4つのストレージシェルフは含まれません。 |
プール1ディスクのディスク割り当ての確認
リモート ディスクがノードに認識され、正しく割り当てられていることを確認する必要があります。
metrocluster configuration-settings connection connectコマンドを使用してMetroCluster IPインターフェイスおよび接続を作成したあと、ディスクの自動割り当てが完了するまでには少なくとも10分かかります。
コマンドの出力には、ディスク名が「ノード名:0m.i1.0L1」の形式で表示されます。
-
プール1のディスクが自動で割り当てられていることを確認します。
disk show
プール1のドライブの手動割り当て
出荷時に事前設定されておらず、自動ドライブ割り当ての要件を満たしていないシステムでは、リモートのプール1ドライブを手動で割り当てる必要があります。
使用するシステムで、手動でディスクを割り当てる必要があるかの詳細については、自動ドライブ割り当てとADPシステムに関する考慮事項を参照してください。
外付けシェルフがサイトあたり2台しかない場合は、次の例に示すように、各サイトのプール1で同じシェルフのドライブを共有する必要があります。
-
node_A_1にsite_B-shelf_2(リモート)のベイ0~11のドライブを割り当て
-
node_A_2にsite_B-shelf_2(リモート)のベイ12~23のドライブを割り当て
-
MetroCluster IP構成の各ノードで、リモート ドライブをプール1に割り当てます。
-
未割り当てドライブのリストを表示します。
disk show -host-adapter 0m -container-type unassignedcluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 6.23.0 - 23 0 SSD unassigned - - 6.23.1 - 23 1 SSD unassigned - - . . . node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . 48 entries were displayed. cluster_A::> -
リモート ドライブ(0m)の所有権を最初のノード(例:node_A_1)のプール1に割り当てます。
disk assign -disk disk-id -pool 1 -owner owner-node-namedisk-idには、owner-node-nameのリモート シェルフのドライブを指定する必要があります。 -
ドライブがプール1に割り当てられたことを確認します。
disk show -host-adapter 0m -container-type unassignedNoteリモート ディスクへのアクセスに使用されるiSCSI接続は、デバイス「0m」と表示されます。 次の出力では、シェルフ23のドライブが割り当てられ、未割り当てドライブのリストに表示されていません。
cluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . node_A_2:0m.i2.1L90 - 21 19 SSD unassigned - - 24 entries were displayed. cluster_A::> -
同じ手順を繰り返して、サイトAの2つ目のノード(例:「node_A_2」)にプール1ドライブを割り当てます。
-
サイトBで同じ手順を繰り返します。
-
ルートアグリゲートのミラーリング
データを保護するためには、ルートアグリゲートをミラーリングする必要があります。
デフォルトでは、ルートアグリゲートはRAID-DPタイプのアグリゲートとして作成されます。ルートアグリゲートをRAID-DPからRAID4タイプアグリゲートに変更できます。次のコマンドは、RAID4タイプアグリゲートのルートアグリゲートを変更します。
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
Note
|
non-ADPシステムでは、アグリゲートがミラーリングされる前またはあとに、アグリゲートのRAIDタイプをデフォルトのRAID-DPからRAID4に変更できます。 |
-
ルートアグリゲートをミラーリングします。
storage aggregate mirror aggr_name次のコマンドは、「controller_A_1」のルートアグリゲートをミラーリングします。
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
これはアグリゲートをミラーリングするため、ローカルプレックスとリモートMetroClusterサイトにあるリモートプレックスで構成されます。
-
MetroCluster設定の各ノードに対して前の手順を繰り返します。
各ノードでのミラーされたデータ アグリゲートの作成
DRグループの各ノードに、ミラーされたデータ アグリゲートを1つ作成する必要があります。
-
新しいアグリゲートで使用するドライブを把握しておきます。
-
複数のドライブ タイプを含むシステム(異機種混在ストレージ)の場合は、正しいドライブ タイプが選択されるようにする方法を確認しておく必要があります。
-
ドライブは特定のノードによって所有されます。アグリゲートを作成する場合、アグリゲート内のすべてのドライブは同一のノードによって所有される必要があります。そのノードが、作成するアグリゲートのホーム ノードになります。
ADPを使用するシステムではパーティションを使用してアグリゲートが作成され、各ドライブがパーティションP1、P2、P3に分割されます。
-
アグリゲート名は、MetroCluster構成を計画する際に決定した命名基準を満たしている必要があります。
-
使用可能なスペアのリストを表示します。
storage disk show -spare -owner node_name -
アグリゲートを作成します。
storage aggregate create -mirror trueクラスタ管理インターフェイスでクラスタにログインした場合、クラスタ内の任意のノードにアグリゲートを作成できます。特定のノードにアグリゲートを作成するには、
-nodeパラメーターを使用するか、そのノードが所有するドライブを指定します。次のいずれかのオプションを指定します。
-
アグリゲートのホーム ノード(通常運用時にアグリゲートを所有するノード)
-
アグリゲートに追加するドライブのリスト
-
追加するドライブ数
Note使用できるドライブ数が限られている最小サポート構成では、force-small-aggregateオプションを使用して、3ディスクのRAID-DPアグリゲートを作成できるように設定する必要があります。 -
アグリゲートに使用するチェックサム形式
-
使用するドライブのタイプ
-
使用するドライブのサイズ
-
使用するドライブの速度
-
アグリゲートのRAIDグループのRAIDタイプ
-
RAIDグループに含めることができるドライブの最大数
-
rpmの異なるドライブの混在を許可するか これらのオプションの詳細については、storage aggregate createコマンドのマニュアル ページを参照してください。
次のコマンドでは、10本のディスクを含むミラーされたアグリゲートが作成されます。
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
新しいアグリゲートのRAIDグループとドライブを確認します。
storage aggregate show-status -aggregate aggregate-name
MetroCluster構成の実装
MetroCluster構成でデータ保護を開始するには、metrocluster configureコマンドを実行する必要があります。
-
ルート以外のミラーされたデータ アグリゲートが各クラスタに少なくとも2つ必要です。
これは
storage aggregate showコマンドで確認できます。Noteミラーされた単一のデータ アグリゲートを使用する場合は、手順1を参照してください。 -
コントローラーおよびシャーシのha-configの状態が「mccip」である必要があります。
metrocluster configureコマンドをいずれかのノードで1回実行し、MetroCluster構成を有効にします。サイトごとまたはノードごとに実行する必要はありません。また、実行するノードまたはサイトはどれでもかまいません。
metrocluster configureコマンドを実行すると、2つのクラスタのそれぞれでシステムIDが最も小さい2つのノードがディザスタ リカバリー(DR)パートナーとして自動的にペアリングされます。4ノードMetroCluster構成の場合は、DRパートナーのペアは2組になります。2つ目のDRペアは、システムIDが大きい2つのノードで作成されます。
|
Note
|
metrocluster configureコマンドを実行する前にオンボード キー マネージャ(OKM)や外部キー管理を設定しないでください。
|
-
MetroCluster構成の内容
操作
複数のデータ アグリゲート
いずれかのノードのプロンプトで、MetroClusterを構成します。
metrocluster configure node-nameミラーされた1つのデータ アグリゲート
-
いずれかのノードのプロンプトで、advanced権限レベルに切り替えます。
set -privilege advancedadvancedモードで続けるかを尋ねられたら、
yと入力して応答する必要があります。advancedモードのプロンプト(*>)が表示されます。 -
-allow-with-one-aggregate trueパラメーターを使用してMetroClusterを設定します。metrocluster configure -allow-with-one-aggregate true node-name -
admin権限レベルに戻ります。
set -privilege admin
Note複数のデータ アグリゲートを使用することを推奨します。最初のDRグループにアグリゲートが1つしかなく、1つのアグリゲートを含むDRグループを追加する場合は、メタデータ ボリュームを単一のデータ アグリゲートから移動する必要があります。 次のコマンドは、「controller_A_1」を含むDRグループ内のすべてのノードのMetroCluster構成を有効にします。
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
サイトAのネットワーク ステータスを確認します。
network port show次の例は、4ノードMetroCluster構成でのネットワーク ポートの使用状況を示しています。
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
MetroCluster構成の両方のサイトからMetroCluster構成を確認します。
-
サイトAから構成を確認します。
metrocluster showcluster_A::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal Remote: cluster_B Configuration state configured Mode normal -
サイトBから構成を確認します。
metrocluster showcluster_B::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal Remote: cluster_A Configuration state configured Mode normal
-
-
不揮発性メモリー ミラーリングで発生する可能性がある問題を回避するため、4つのノードをそれぞれリブートします。
node reboot -node node-name -inhibit-takeover true -
両方のクラスタで
metrocluster showコマンドを実行し、もう一度構成を確認します。
8ノード構成での2つ目のDRグループの設定
上記のタスクを繰り返して、2つ目のDRグループのノードを設定します。
ミラーされていないデータ アグリゲートの作成
MetroCluster構成が提供する冗長なミラーリングを必要としないデータについては、必要に応じてミラーされていないデータ アグリゲートを作成できます。
-
新しいアグリゲートで使用するドライブまたはアレイLUNを把握しておきます。
-
複数のドライブ タイプを含むシステム(異機種混在ストレージ)の場合は、正しいドライブ タイプが選択されていることを確認する方法を理解しておく必要があります。
|
Important
|
MetroCluster IP構成では、スイッチオーバー後はミラーされていないリモート アグリゲートにはアクセスできません。 |
|
Note
|
ミラーされていないアグリゲートは、そのアグリゲートを所有するノードに対してローカルである必要があります。 |
-
ドライブとアレイLUNは特定のノードによって所有されます。アグリゲートを作成する場合、アグリゲート内のすべてのドライブは、同一のノードによって所有される必要があります。そのノードが、作成するアグリゲートのホーム ノードになります。
-
アグリゲート名は、MetroCluster構成を計画する際に決定した命名基準を満たしている必要があります。
-
アグリゲートのミラーリングの詳細については、「ディスクおよびアグリゲートの管理」を参照してください。
-
ミラーされていないアグリゲートの配置を有効にします。
metrocluster modify -enable-unmirrored-aggr-deployment true -
自動ディスク割り当てが無効になっていることを確認します。
disk option show -
ミラーされていないアグリゲートを格納するディスク シェルフを設置してケーブル接続します。
手順については、使用するプラットフォームとディスク シェルフの設置とセットアップのドキュメントを参照してください。
-
新しいシェルフのすべてのディスクを適切なノードに手動で割り当てます。
disk assign -disk disk-id -owner owner-node-name -
アグリゲートを作成します。
storage aggregate createクラスタ管理インターフェイスでクラスタにログインした場合、クラスタ内の任意のノードにアグリゲートを作成できます。特定のノードにアグリゲートが作成されたことを確認するには、-nodeパラメーターを使用するか、そのノードが所有するドライブを指定します。
また、アグリゲートにはミラーされていないシェルフのドライブだけを追加する必要があります。
次のいずれかのオプションを指定します。
-
アグリゲートのホーム ノード(通常運用時にアグリゲートを所有するノード)
-
アグリゲートに追加するドライブまたはアレイLUNのリスト
-
追加するドライブ数
-
アグリゲートに使用するチェックサム形式
-
使用するドライブのタイプ
-
使用するドライブのサイズ
-
使用するドライブの速度
-
アグリゲートのRAIDグループのRAIDタイプ
-
RAIDグループに含めることができるドライブまたはアレイLUNの最大数
-
rpmの異なるドライブの混在を許可するか
これらのオプションの詳細については、storage aggregate createコマンドのマニュアル ページを参照してください。
次のコマンドでは、10本のディスクを含むミラーされていないアグリゲートが作成されます。
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
新しいアグリゲートのRAIDグループとドライブを確認します。
storage aggregate show-status -aggregate aggregate-name -
ミラーされていないアグリゲートの配置を無効にします。
metrocluster modify -enable-unmirrored-aggr-deployment false -
自動ディスク割り当てが有効になっていることを確認します。
disk option show
MetroCluster構成の確認
MetroCluster構成内のコンポーネントおよび関係が正しく機能していることを確認できます。
チェックは、初期設定後と、MetroCluster構成に変更を加えたあとに実施する必要があります。
また、ネゴシエート(計画的)スイッチオーバーやスイッチバックの処理の前にも実施します。
一方または両方のクラスタに対してmetrocluster check runコマンドを短時間に2回実行すると、競合が発生してすべてのデータが収集されない場合があります。その結果、metrocluster check showコマンドで想定した出力が表示されなくなります。
-
構成を確認します。
metrocluster check runこのコマンドはバックグラウンド ジョブとして実行され、すぐに完了しない場合があります。
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
最後に実行したmetrocluster check runコマンドから、より詳細な結果を表示します。
metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node showNotemetrocluster check showコマンドを実行すると、最後に実行したmetrocluster check runコマンドの結果が表示されます。最新の情報を表示するために、metrocluster check showコマンドを使用する前に必ずmetrocluster check runコマンドを実行してください。次の例は、正常な4ノードMetroCluster構成の
metrocluster check aggregate showコマンドの出力を示しています。cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.次の例は、正常な4ノードMetroCluster構成のmetrocluster check cluster showコマンドの出力を示しています。この出力は、必要に応じてネゴシエート スイッチオーバーを実行できる状態であることを示しています。
Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
ONTAP設定の完了
MetroCluster構成の設定、有効化、および確認が完了したら、必要に応じてSVM、ネットワーク インターフェイス、およびその他のONTAP機能を追加してクラスタの設定を完了します。