
![]()
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
MetroCluster マニュアル ( CA08871-401 )
MetroClusterのデータ保護およびディザスタ リカバリーの概要
MetroClusterでデータ保護と障害からの透過的なリカバリーが実装される仕組みを理解することで、スイッチオーバーとスイッチバックの作業を簡単かつ効率的に実施できます。
MetroClusterは、ミラーリングを使用してクラスタ内のデータを保護します。ディザスタ リカバリーは1つのMetroClusterコマンドで実装されます。このコマンドは、サバイバー サイトのセカンダリーをアクティブ化して、災害の影響を受けたプライマリー サイトが本来所有していた、ミラーリングされたデータを提供できるようにします。
8ノード / 4ノードMetroCluster構成でのローカル フェイルオーバーとスイッチオーバー
8ノード / 4ノードMetroCluster構成では、ローカル レベルとクラスタ レベルの両方でデータが保護されます。MetroCluster構成をセットアップする場合は、MetroCluster構成がどのようにデータを保護するかを理解しておく必要があります。
MetroCluster構成は、物理的に分離され、ミラーされた2つのクラスタを使用することでデータを保護します。各クラスタで、もう一方のクラスタのデータおよびStorage Virtual Machine(SVM)の設定が同期的にミラーされます。一方のサイトで災害が発生すると、管理者は、ミラーされたSVMをアクティブ化し、サバイバー サイトからミラーされたデータの提供を開始することができます。さらに、各クラスタ内のノードはHAペアとして構成されているため、ローカル フェイルオーバーも可能になります。
MetroCluster構成でのローカルのHAデータ保護の仕組み
MetroCluster構成でのHAペアの仕組みを理解する必要があります。
ピア ネットワークにある2つのクラスタは、それぞれがもう一方のクラスタのソース クラスタまたはバックアップ クラスタになることで、双方向のディザスタ リカバリーを実現します。各クラスタは、HAペアとして構成された2つのノードで構成されます。1つのノード構成内で障害が発生した場合やメンテナンスが必要な場合、ストレージ フェイルオーバーによって、そのノードの機能をローカルのHAパートナーに転送することができます。
MetroCluster構成でのデータと設定のレプリケーション
MetroCluster構成では、各種のONTAP機能を使用して、2つのMetroClusterサイトの間でデータと設定の同期レプリケーションが行われます。
設定レプリケーション サービスによる設定の保護
ONTAPのConfiguration Replication Service(CRS;設定レプリケーション サービス)は、DRパートナーに情報を自動的にレプリケートしてMetroCluster構成を保護します。
CRSは、ローカル ノードの設定をパートナー クラスタのDRパートナーに同期的にレプリケートします。このレプリケーションは、クラスタ ピアリング ネットワーク経由で行われます。
レプリケートされる情報には、クラスタの設定とSVMの設定が含まれます。
MetroCluster処理中のSVMのレプリケート
ONTAPのConfiguration Replication Service(CRS;設定レプリケーション サービス)は、冗長なデータ サーバー構成とSVMに属するデータ ボリュームのミラーリングを提供します。スイッチオーバーでは、ソースSVMが停止し、サバイバー クラスタ上にあるデスティネーションSVMがアクティブになります。
MetroCluster構成のデスティネーションSVMの名前には、識別しやすいようにサフィックス「-mc」が自動的に付加されます。MetroCluster構成では、デスティネーションSVMの名前にサフィックス「-mc」が付加されます。SVM名にピリオドが含まれている場合は、最初のピリオドの前にサフィックス「-mc」が付加されます。例えば、SVM名がSVM.DNS.NAMEの場合、サフィックス「-mc」を付加したあとの名前はSVM-MC.DNS.NAMEとなります。
|
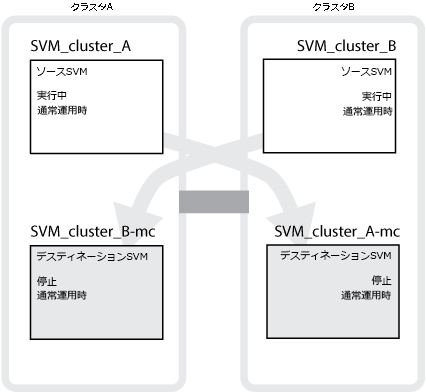
次の例は、MetroCluster構成のSVMを示しています。「SVM_cluster_A」はソース サイトのSVM、「SVM_cluster_A-mc」はディザスタ リカバリー サイトの同期先のアグリゲートです。
-
SVM_cluster_AはクラスタAのデータを提供します。
これは同期元のSVMであり、SVMの設定(LIF、プロトコル、サービス)およびSVMに属するボリュームのデータを表します。設定とデータは、クラスタBにある同期先のSVM、SVM_cluster_A-mcにレプリケートされます。
-
SVM_cluster_BはクラスタBのデータを提供します。
これは同期元のSVMであり、クラスタAにあるSVM_cluster_B-mcに対する設定とデータを表します。
-
SVM_cluster_B-mcは同期先のSVMであり、MetroCluster構成が通常どおり正常に動作している間は停止しています。
クラスタBからクラスタAへのスイッチオーバーが成功するとSVM_cluster_Bは停止し、SVM_cluster_B-mcがアクティブになって、クラスタAのデータ提供を開始します。
-
SVM_cluster_A-mcは同期先のSVMであり、MetroCluster構成が通常どおり正常に動作している間は停止しています。
クラスタAからクラスタBへのスイッチオーバーが成功するとSVM_cluster_Aは停止し、SVM_cluster_A-mcがアクティブになって、クラスタBのデータ提供を開始します。
スイッチオーバーが行われると、サバイバー クラスタ上のリモート プレックスがオンラインになり、セカンダリーSVMがデータの提供を開始します。
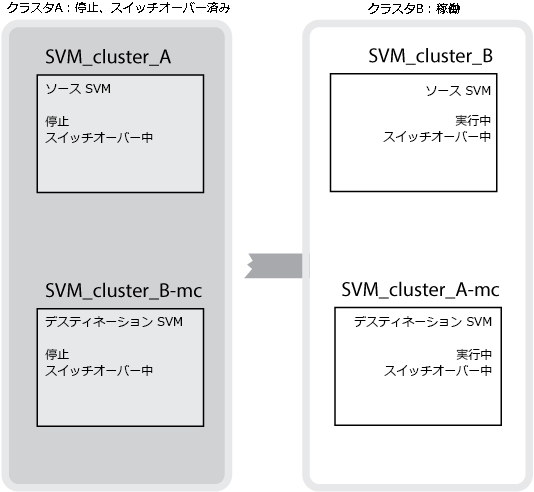
スイッチオーバー後にリモート プレックスを使用できるかは、MetroCluster構成のタイプによって決まります。
-
MetroCluster IP構成でリモート プレックスを使用できるかは、ONTAPのバージョンによって決まります。
-
ONTAPでは、ディザスタ サイトのノードがブートしたままの場合、ローカル プレックスとリモート プレックスの両方がオンラインのままになります。
-
MetroCluster構成でのSyncMirrorを使用したデータ冗長性の実現
SyncMirror機能を使用するミラーされたアグリゲートにはソースとデスティネーションのStorage Virtual Machine(SVM)が所有するボリュームが格納され、データの冗長性が確保されます。データはパートナー クラスタのディスク プールにレプリケートされます。ミラーされていないアグリゲートもサポートされます。
次の表に、スイッチオーバー後のミラーされていないアグリゲートの状態(オンラインまたはオフライン)を示します。
h |
スイッチオーバーのタイプ h |
MetroCluster IP構成の状態 |
ネゴシエート スイッチオーバー(NSO) |
オフライン(注1) |
自動計画外スイッチオーバー(AUSO) |
オフライン(注1) |
計画外スイッチオーバー(USO) |
オフライン(注1) |
注1:MetroCluster IP構成では、スイッチオーバーの完了後に、ミラーされていないアグリゲートを手動でオンラインにすることができます。
| スイッチオーバー後に、ミラーされていないアグリゲートがDRパートナー ノードにある状態でスイッチ間リンク(ISL)に障害が発生すると、そのローカル ノードで障害が発生することがあります。 |
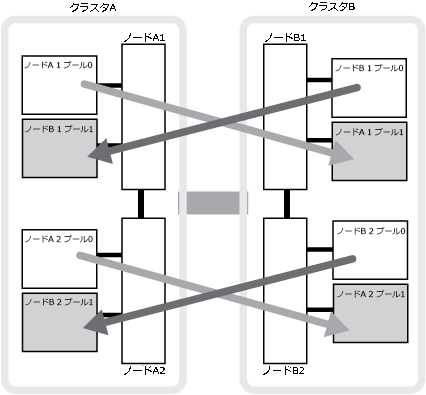
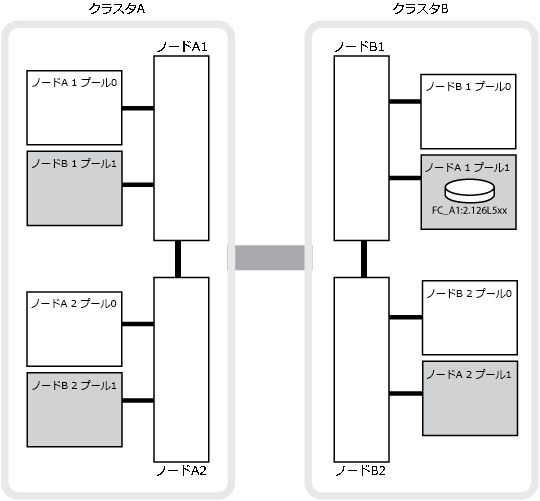
次の図は、ディスク プールがパートナー クラスタ間でミラーされる仕組みを示しています。ローカル プレックス(プール0内)のデータは、リモート プレックス(プール1内)にレプリケートされます。
| ハイブリッド アグリゲートを使用している場合、ソリッド ステート ディスク(SSD)レイヤーの空きスペースがなくなったことが原因でSyncMirrorプレックスに障害が発生すると、パフォーマンスが低下する可能性があります。 |
MetroCluster構成でのNVRAM / NVMEMキャッシュ ミラーリングと動的ミラーリング
ストレージ コントローラーの不揮発性メモリー(プラットフォーム モデルに応じてNVRAMまたはNVMEM)は、ローカルHAパートナーにローカルでミラーされ、同時にパートナー サイトのリモート ディザスタ リカバリー(DR)パートナーにリモートでミラーされます。この構成により、ローカルでフェイルオーバーまたはスイッチオーバーが発生しても、不揮発性キャッシュ内のデータを保護することができます。
MetroCluster構成に含まれていないHAペアでは、各ストレージ コントローラーが不揮発性キャッシュ パーティションを2つ(当該コントローラーとそのHAパートナー用に1つずつ)使用します。
4ノードMetroCluster構成では、各ストレージ コントローラーの不揮発性キャッシュが4つのパーティションに分かれています。2ノードMetroCluster構成では、ストレージ コントローラーがHAペアとして構成されないため、HAパートナー パーティションとDR補助パーティションが使用されません。
ストレージ コントローラーの不揮発性キャッシュ |
|
|---|---|
MetroCluster構成 |
MetroClusterに属さないHAペア |
|
|
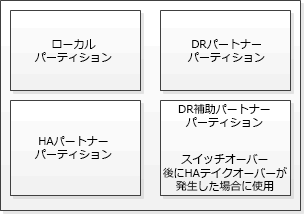
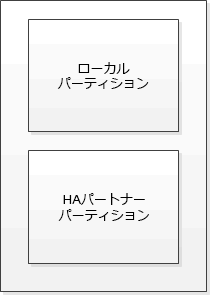
不揮発性キャッシュには次のデータが格納されます。
-
ローカル パーティションは、ストレージ コントローラーからディスクに書き込まれる前のデータを格納します。
-
HAパートナー パーティションは、HAパートナーのローカル キャッシュのコピーを格納します。
2ノードMetroCluster構成では、ストレージ コントローラーがHAペアとして構成されないため、HAパートナー パーティションは存在しません。
-
DRパートナー パーティションは、DRパートナーのローカル キャッシュのコピーを格納します。
DRパートナーは、ローカル ノードと対の関係にあるパートナー クラスタ内のノードです。
-
DR HA パートナー パーティションは、DR HA パートナーのローカル キャッシュのコピーを格納します。
DR HA パートナーは、ローカル ノードのDRパートナーのHAパートナーです。このキャッシュは、HAテイクオーバーが実行された場合(構成の通常動作中またはMetroClusterスイッチオーバー後)に必要です。
2ノードMetroCluster構成では、ストレージ コントローラーがHAペアとして構成されないため、DR HA パートナー パーティションは存在しません。
例えば、ノード(node_A_1)のローカル キャッシュは、MetroClusterサイトでローカルおよびリモートの両方でミラーされます。次の図では、node_A_1のローカル キャッシュが、HAパートナー(node_A_2)とDRパートナー(node_B_1)にミラーされています。
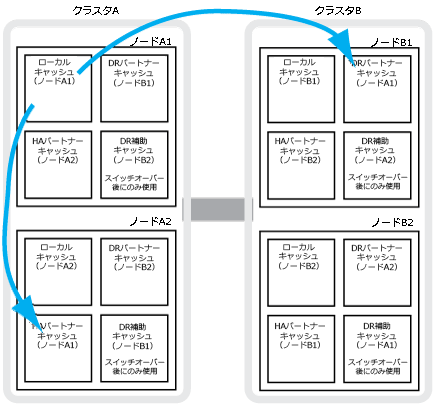
ローカルのHAテイクオーバー時の動的なミラーリング
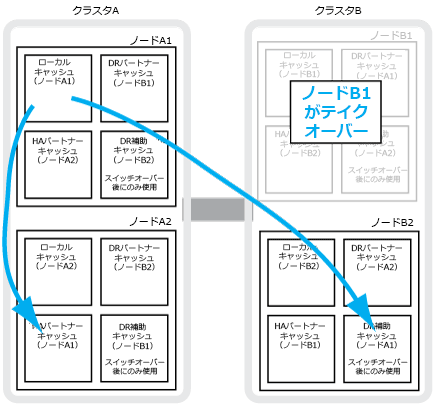
4ノードMetroCluster構成でローカルのHAテイクオーバーが行われると、テイクオーバーされたノードはDRパートナーのミラーとして機能しなくなります。DRミラーリングを続行するために、ミラーリング先が自動的にDR HA パートナーへと切り替わります。ギブバックが正常に終了すると、ミラーリング先は自動的にDRパートナーに戻ります。
例えば、node_B_1で障害が発生し、node_B_2によってテイクオーバーされたとします。この場合、node_A_1のローカル キャッシュをnode_B_1にミラーできなくなり、ミラーリング先がDR HA パートナーnode_B_2に切り替わります。
災害の種類とリカバリー方法
MetroCluster構成を使用して適切に対応できるように、各種の障害や災害について熟知しておく必要があります。
-
単一ノード障害
ローカルHAペアの1つのコンポーネントで発生する障害です。
4ノードのMetroCluster構成の場合、障害が発生したコンポーネントによっては、障害ノードの自動テイクオーバーまたはネゴシエート テイクオーバーが行われる可能性があります。データ リカバリーについては、ハイアベイラビリティ ペアの管理で説明します。
2ノードMetroCluster構成の場合は、自動計画外スイッチオーバー(AUSO)が行われます。
-
サイト全体のコントローラー障害
電力供給の停止、機器の交換、または災害が原因で、サイトにあるすべてのコントローラー モジュールで障害が発生します。通常、MetroCluster構成では障害と災害を区別できません。しかし、MetroCluster Tiebreakerソフトウェアなどの監視ソフトウェアはこれらを区別できます。スイッチ間リンク(ISL)およびスイッチが稼働しており、ストレージにアクセスできる場合は、サイト全体のコントローラー障害によって自動スイッチオーバーが実行される可能性があります。
ハイアベイラビリティ ペアの管理には、サイト全体のコントローラー障害、および1台以上のコントローラーを含む障害からのリカバリー方法が詳しく記載されています。
-
ISL障害
サイト間のリンクで発生する障害です。MetroCluster構成による対応はありません。各ノードは通常どおりデータを提供しますが、対応するディザスタ リカバリー サイトにアクセスできないため、ミラー データの書き込みは行われません。
-
複数の連続的な障害
複数のコンポーネントで連続して発生する障害です。例えば、コントローラー モジュール、スイッチ ファブリック、およびシェルフで連続して障害が発生した結果、ダウンタイムやデータ損失から保護するために、ストレージのフェイルオーバー、ファブリックの冗長処理、およびSyncMirrorが順次行われる場合です。
次の表に、障害の種類、および対応するディザスタ リカバリー(DR)メカニズムとリカバリー方法を示します。
| MetroCluster IP構成では、自動計画外スイッチオーバー(AUSO)はサポートされません。 |
障害タイプ |
DRメカニズム |
リカバリー方法の概要 |
||
|---|---|---|---|---|
4ノード構成 |
2ノード構成 |
4ノード構成 |
2ノード構成 |
|
単一ノード障害 |
ローカルHAフェイルオーバー |
AUSO |
自動フェイルオーバーとギブバックが有効になっている場合は必要なし。 |
ノードがリストアされたら、 |
サイト障害 |
MetroClusterスイッチオーバー |
ノードがリストアされたら、 |
||
サイト全体のコントローラー障害 |
AUSO。ディザスタ サイトのストレージにアクセスできる場合のみ。 |
AUSO(単一ノード障害と同じ) |
||
複数の連続的な障害 |
ローカルHAフェイルオーバーのあとに、 NOTE: 障害が発生したコンポーネントによっては、強制スイッチオーバーは不要。 |
|
||
ISL障害 |
MetroClusterのスイッチオーバーなし。2つのクラスタがそれぞれのデータを独立して提供。 |
必要なし。接続が回復すると、ストレージは自動的に再同期されます。 |
||
8ノード / 4ノードMetroCluster構成でのノンストップ オペレーションの実現
8ノード / 4ノードのMetroCluster構成は各サイトに1つ以上のHAペアで構成されるため、それぞれのサイトでのローカルな障害には、パートナー サイトにスイッチオーバーしなくても対応でき、サービスが中断することはありません。HAペアの動作は、非MetroCluster構成のHAペアと同じです。
4ノードと8ノードのMetroCluster構成では、パニックまたは停電によるノード障害が発生すると、自動スイッチオーバーが動作することがあります。
ローカル フェイルオーバー後に2回目の障害が発生した場合、MetroClusterのスイッチオーバー イベントによって、中断のないノンストップ オペレーションが実現します。同様に、スイッチオーバー処理後にサバイバー ノードの1つで次の障害が発生すると、ローカルのフェイルオーバー イベントによってノンストップ オペレーションが継続されます。この場合、正常に稼働している1つのノードが、DRグループ内の他の3ノードにデータを提供します。
2ノードMetroCluster構成でのノンストップ オペレーションの実現
2つのサイトのどちらかでパニックによる問題が発生した場合は、MetroClusterスイッチオーバーによってノンストップ オペレーションが継続されます。停電によってノードとストレージの両方が影響を受けた場合は、スイッチオーバーが自動的に行われず、metrocluster switchoverコマンドを実行するまでシステムが停止します。
すべてのストレージはミラーリングされるため、ノード障害でのHAペアのストレージフェイルオーバーの場合と同じように、サイト障害が発生した場合は、スイッチオーバー操作を使用して無停止の耐障害性を実現できます。
2ノード構成では、HAペアで自動ストレージ フェイルオーバーをトリガーするイベントと同じイベントによって、自動計画外スイッチオーバー(AUSO)がトリガーされます。つまり、2ノードMetroCluster構成ではHAペアと同じ保護レベルが確保されます。
スイッチオーバー プロセスの概要
MetroClusterのスイッチオーバー処理では、ストレージとクライアントのアクセスをソース クラスタからリモート サイトに移動することで、災害発生後にサービスを即座に再開できます。スイッチオーバーが発生した場合に予想される変更や、実行する必要があるアクションを把握しておく必要があります。
スイッチオーバー処理中に、システムは次の処理を実行します。
-
ディザスタ サイトに属するディスクの所有権がディザスタ リカバリー(DR)パートナーに変更されます。
これは、停止中のパートナーに属するディスクの所有権が正常な状態のパートナーに変更されるハイアベイラビリティ(HA)ペアでのローカル フェイルオーバーと似ています。
-
サバイバー サイトにあるサバイバー プレックスがディザスタ クラスタ内のノードに属する場合、そのサバイバー プレックスは、サバイバー サイトのクラスタでオンラインになります。
-
ディザスタ サイトに属する同期元のStorage Virtual Machine(SVM)が、ネゴシエート スイッチオーバーの実行中のみ停止されます。
この処理は、ネゴシエート スイッチオーバーにのみ該当します。 -
ディザスタ サイトに属する同期先のSVMが起動されます。
スイッチオーバー中は、DRパートナーのルート アグリゲートはオンラインになりません。
metrocluster switchoverコマンドは、MetroCluster構成にあるすべてのDRグループのノードを切り替えます。例えば、8ノードMetroCluster構成では、両方のDRグループのノードをスイッチオーバーします。
サービスのみをリモート サイトにスイッチオーバーする場合は、サイトをフェンシングせずにネゴシエート スイッチオーバーを実行します。ストレージまたは機器を信頼できない場合は、ディザスタ サイトをフェンシングしてから、計画外スイッチオーバーを実行する必要があります。フェンシングにより、ディスクに電源が順次投入されたときのRAIDの再構築が回避されます。
| この手順は、もう一方のサイトが安定しておりオフラインにすることがない場合にのみ使用してください。 |
スイッチオーバー中に使用できるコマンド
次の表は、スイッチオーバー中に実行できるコマンドの一覧です。
コマンド |
利用可否に関する補足 |
|---|---|
|
次のアグリゲートを作成できます。
次のアグリゲートは作成できません。
|
|
データ アグリゲートを削除できます。 |
|
ミラーされていないアグリゲートのプレックスを作成できます。 |
|
ミラーされたアグリゲートのプレックスを削除できます。 |
|
次のSVMを作成できます。
次のSVMは作成できません。
|
|
同期元と同期先の両方のSVMを削除できます。 |
|
同期元と同期先の両方のSVMのデータSVM LIFを作成できます。 |
|
同期元と同期先の両方のSVMのデータSVM LIFを削除できます。 |
|
同期元と同期先の両方のSVMのボリュームを作成できます。
|
|
同期元と同期先の両方のSVMのボリュームを削除できます。 |
|
同期元と同期先の両方のSVMのボリュームを移動できます。
|
|
データ保護ミラーのソースとデスティネーションのエンドポイント間のSnapMirror関係を解除できます。 |
4ノードMetroCluster構成でのHAテイクオーバー中およびMetroClusterスイッチオーバー中のディスク所有権の変更
ハイアベイラビリティ処理およびMetroCluster処理中、ディスク所有権が一時的に変更されます。どのノードがどのディスクを所有するかをシステムが追跡する仕組みを把握しておくと役に立ちます。
ONTAPは、コントローラー モジュールの固有なシステムID(ノードのNVRAMカードまたはNVMEMボードから取得)を使用して、どのノードがどの特定のディスクを所有するかを識別します。システムのHAまたはDRの状態によっては、ディスク所有権が一時的に変わる場合があります。HAテイクオーバーまたはDRスイッチオーバーによって所有権が変わった場合、HAギブバックまたはDRスイッチバックの終了後に所有権を元に戻すことができるよう、どのノードがディスクの元々の(「ホーム」)所有者であるかが記録されます。ディスク所有権の追跡には次のフィールドが使用されます。
-
所有者
-
ホーム所有者
-
DRホーム所有者
MetroCluster構成でスイッチオーバーが実行された場合、ノードは、パートナー クラスタのノードが元々所有していたアグリゲートの所有権を取得できます。このようなアグリゲートは「クラスタ外アグリゲート」と呼ばれます。クラスタ外アグリゲートはその時点でクラスタに認識されていないアグリゲートで、したがって、DRホーム所有者フィールドにはパートナー クラスタのノードが所有者として表示されます。HAペア内の従来の外部アグリゲートは所有者とホーム所有者の値が異なりますが、クラスタ外アグリゲートは所有者とホーム所有者の値が同じであるため、DRホーム所有者の値で識別できます。
システムの状態が変化するにしたがい、これらのフィールドの値も次の表に示すように変わります。
フィールド |
状況別の値 |
|||
|---|---|---|---|---|
通常動作 |
ローカルのHAテイクオーバー |
MetroClusterスイッチオーバー |
スイッチオーバー中のテイクオーバー |
|
所有者 |
ディスクにアクセスできるノードのID |
一時的にディスクにアクセスできるHAパートナーのID |
一時的にディスクにアクセスできるDRパートナーのID |
一時的にディスクにアクセスできるDR HA パートナーのID |
ホーム所有者 |
HAペア内の元のディスク所有者のID |
HAペア内の元のディスク所有者のID |
スイッチオーバー中にHAペアのホーム所有者となるDRパートナーのID |
スイッチオーバー中にHAペアのホーム所有者となるDRパートナーのID |
DRホーム所有者 |
空き |
空き |
MetroCluster構成内の元のディスク所有者のID |
MetroCluster構成内の元のディスク所有者のID |
次の図と表は、物理的にはcluster_Bに配置されているnode_A_1のディスク プール1のディスクについて、所有権が変化する例を示しています。
MetroClusterの状態 |
所有者 |
ホーム所有者 |
DRホーム所有者 |
注 |
|---|---|---|---|---|
通常の状態:すべてのノードが完全に動作 |
node_A_1 |
node_A_1 |
該当なし |
|
ローカルのHAテイクオーバー:node_A_2がHAパートナーnode_A_1に属するディスクをテイクオーバー |
node_A_2 |
node_A_1 |
該当なし |
|
DRスイッチオーバー:node_B_1がDRパートナーnode_A_1に属するディスクをテイクオーバー |
node_B_1 |
node_B_1 |
node_A_1 |
元のホームノードIDはDRホーム所有者フィールドに移動します。アグリゲートのスイッチバックまたは修復後、所有権はnode_A_1に戻ります。 |
DRのスイッチオーバーとローカルのHAテイクオーバー(二重障害):node_B_2がHA node_B_1に属するディスクをテイクオーバー |
node_B_2 |
node_B_1 |
node_A_1 |
ギブバック後、所有権はnode_B_1に戻ります。スイッチバックまたは修復後、所有権はnode_A_1に戻ります。 |
HAギブバックおよびDRスイッチバック後:すべてのノードが完全に動作 |
node_A_1 |
node_A_1 |
該当なし |
ミラーされていないアグリゲートを使用する場合の考慮事項
ミラーされていないアグリゲートが構成に含まれている場合、スイッチオーバー処理後にアクセスに関する問題が発生する可能性があります。
電源の切断が必要なメンテナンス実施時のミラーされていないアグリゲートに関する考慮事項
サイト全体の電源の切断が必要なメンテナンスのためにネゴシエート スイッチオーバーを実行する場合は、最初にディザスタ サイトが所有するミラーされていないアグリゲートを手動でオフラインにする必要があります。
オフラインにしない場合は、複数のディスクがパニック状態になって、サバイバー サイトのノードが停止する可能性があります。この問題が発生するのは、電源の切断またはISLの喪失によってディザスタ サイトのストレージへの接続が失われたために、スイッチオーバーされたミラーされていないアグリゲートがオフラインになるか、または見つからない場合です。
ミラーされていないアグリゲートと階層状のネームスペースに関する考慮事項
階層状のネームスペースを使用している場合は、パス内のすべてのボリュームがミラーされたアグリゲートのみ、またはミラーされていないアグリゲートのみに配置されるようにジャンクション パスを設定する必要があります。ジャンクション パスにミラーされていないアグリゲートとミラーされたアグリゲートが混在していると、スイッチオーバー処理後にミラーされていないアグリゲートにアクセスできなくなる可能性があります。
ミラーされていないアグリゲート、CRSメタデータ ボリューム、およびデータSVMのルート ボリュームに関する考慮事項
設定レプリケーション サービス(CRS)メタデータ ボリュームとデータSVMのルート ボリュームは、ミラーされたアグリゲートに配置する必要があります。これらのボリュームをミラーされていないアグリゲートに移動することはできません。ミラーされていないアグリゲートに配置されている場合、ネゴシエート スイッチオーバー処理とスイッチバック処理が拒否されます。その場合、metrocluster checkコマンドによって警告が表示されます。
ミラーされていないアグリゲートとSVMに関する考慮事項
SVMは、ミラーされたアグリゲートでのみ、またはミラーされていないアグリゲートでのみ設定する必要があります。ミラーされていないアグリゲートとミラーされたアグリゲートが混在しているとスイッチオーバー処理に2分以上かかり、ミラーされていないアグリゲートがオンラインにならない場合にデータを利用できなくなることがあります。
ミラーされていないアグリゲートとSANに関する考慮事項
ミラーされていないアグリゲートにはLUNを配置しないでください。ミラーされていないアグリゲートにLUNを設定すると、スイッチオーバー処理に2分以上かかってデータを利用できなくなることがあります。
MetroCluster IP構成でのMediator アシスト自動計画外スイッチオーバー
修復時の動作(MetroCluster IP構成)
MetroCluster IP構成での修復では、ミラーされたアグリゲートの再同期が実施され、修復されたディザスタ サイトのノードがスイッチバックに向けて準備されます。これは計画的なイベントです。したがって、各手順を細かく制御してダウンタイムを最小限にすることができます。修復は、ストレージとコントローラーのコンポーネントで発生する、2段階のプロセスです。
データ アグリゲートの修復
ディザスタ サイトでの問題が解決したら、ストレージ修復フェーズを開始します。
-
サバイバー サイトで、すべてのノードが稼働中であることを確認します。
-
ルート アグリゲートを含め、ディザスタ サイトのプール0のすべてのディスクの所有権を変更します。
このフェーズでは、RAIDサブシステムがミラーされたアグリゲートを再同期し、WAFLサブシステムが、スイッチオーバー時にプール1プレックスで障害が発生したミラーされたアグリゲートのnvsaveファイルを再実行します。
ソースのストレージ コンポーネントの一部で障害が発生した場合は、該当するレベル(Storage、Sanown、またはRAID)でエラーが報告されます。
エラーが何も報告されなければ、アグリゲートの再同期は成功です。このプロセスは、完了までに数時間かかることがあります。
ルート アグリゲートの修復
アグリゲートの同期が完了したら、ルート アグリゲートの修復フェーズを実行します。MetroCluster IP構成では、アグリゲートが修復されたことをこのフェーズで確認します。
スイッチオーバー後のMetroCluster IP構成でのアグリゲートの自動修復
MetroCluster IP構成では、ネゴシエート スイッチオーバー処理の実行中に自動的に修復が実行されます。計画外スイッチオーバー後の自動修復がサポートされます。これにより、metrocluster healコマンドを実行する必要がなくなります。
ネゴシエート スイッチオーバー後の自動修復(ONTAP 9.5以降)
ネゴシエート スイッチオーバー(-forced-on-disaster trueオプションを指定せずにスイッチオーバー コマンドを実行)の実施後、システムを通常動作に戻すために必要な手順が自動修復機能によって実行されます。自動修復に対応したシステムでは、スイッチオーバー後に次の状況が発生します。
-
ディザスタ サイトのノードは稼働したままです。
これらのノードはスイッチオーバーされているため、ローカルのミラーされたプレックスからはデータを提供していません。
-
ディザスタ サイトのノードが「
Waiting for switchback」状態に移行します。ディザスタ サイトのノードのステータスは、metrocluster operation showコマンドで確認できます。
-
修復コマンドを実行せずにスイッチバック処理を実行できます。
この機能は、ONTAP 9.5以降を実行するMetroCluster IP構成に該当します。MetroCluster FC構成には適用されません。
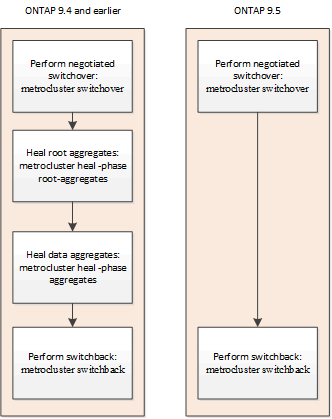
計画外スイッチオーバー後の自動修復
MetroCluster IP構成では、計画外スイッチオーバー後の自動修復がサポートされます。計画外スイッチオーバーでは、-forced-on-disaster trueオプションを指定してswitchoverコマンドを実行します。
ONTAP 9.7以降を実行するシステムでは、計画外スイッチオーバー後に次の状況が発生します。
-
災害の規模によっては、ディザスタ サイトのノードが停止します。
これらのノードはスイッチオーバーされているため、電源が入っていてもローカルのミラーされたプレックスからはデータを提供していません。
-
ディザスタ サイトが停止していた場合は、ブート時にディザスタ サイトのノードが「
Waiting for switchback」状態に移行します。ディザスタ サイトが稼働していた場合は、ただちに「
Waiting for switchback」状態に移行します。 -
修復処理が自動的に実行されます。
ディザスタ サイトのノードのステータスおよび修復処理が成功したかは、
metrocluster operation showコマンドで確認できます。
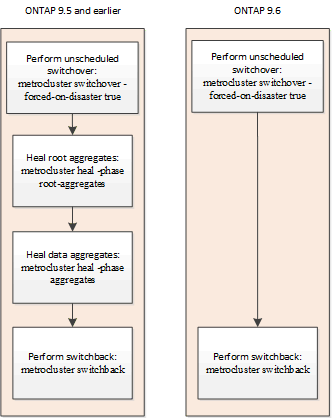
自動修復が失敗した場合
何らかの理由で自動修復処理が失敗した場合は、ONTAP 9.6より前のバージョンのONTAPと同様に、metrocluster healコマンドを手動で実行する必要があります。metrocluster operation showコマンドとmetrocluster operation history show -instanceコマンドを使用して、修復のステータスを監視し、障害の原因を特定できます。
MetroCluster構成用SVMの作成
MetroCluster構成用のSVMを作成して、MetroCluster構成用に設定されたクラスタのデータに対して同期ディザスタ リカバリーおよび高可用性を提供できます。
-
2つのクラスタがMetroCluster構成になっている必要があります。
-
両方のクラスタ内でアグリゲートが利用可能でオンラインになっている必要があります。
-
必要に応じて、両方のクラスタに同じ名前のIPspaceを作成しておく必要があります。
-
MetroCluster構成を形成する一方のクラスタをスイッチオーバーを使用せずにリブートすると、同期元SVMが「
started」ではなく「stopped」の状態でオンラインになることがあります。
MetroCluster構成のどちらかのクラスタにSVMを作成する場合、そのSVMはソースSVMとして作成されます。パートナーSVMは同じ名前で自動的に作成されますが、パートナー クラスタには「-mc」というサフィックスが付加されます。SVM名にピリオドが含まれている場合は、最初のピリオドの前にサフィックス「-mc」が付加されます(例:SVM-MC.DNS.NAME)。
MetroCluster構成では、1つのクラスタに64個のSVMを作成できます。したがって、MetroCluster構成は最大128個のSVMをサポートします。
-
vserver createコマンドを使用します。次の例は、ローカル サイトのSVM(サブタイプが「
sync-source」)とパートナー サイトのSVM(サブタイプが「sync-destination」)を示しています。cluster_A::>vserver create -vserver vs4 -rootvolume vs4_root -aggregate aggr1 -rootvolume-security-style mixed [Job 196] Job succeeded: Vserver creation completed
ローカル サイトにSVM 「
vs4」が作成され、パートナー サイトにSVM 「vs4-mc」が作成されます。 -
新しく作成されたSVMを表示します。
-
ローカル クラスタで、SVMの設定状態を確認します。
metrocluster vserver show次の例は、パートナーSVMとその設定状態を示しています。
cluster_A::> metrocluster vserver show Partner Configuration Cluster Vserver Vserver State --------- -------- --------- ----------------- cluster_A vs4 vs4-mc healthy cluster_B vs1 vs1-mc healthy -
ローカル クラスタとパートナー クラスタから、新しく設定したSVMの状態を確認します。
vserver show command次の例は、SVMの管理状態と運用状態を表示します。
cluster_A::> vserver show Admin Operational Root Vserver Type Subtype State State Volume Aggregate ------- ----- ------- ------- -------- ----------- ---------- vs4 data sync-source running running vs4_root aggr1 cluster_B::> vserver show Admin Operational Root Vserver Type Subtype State State Volume Aggregate ------- ----- ------- ------ --------- ----------- ---------- vs4-mc data sync-destination running stopped vs4_root aggr1
ルート ボリュームの作成などの中間処理が失敗し、SVMの状態が「
initializing」になっている場合は、SVMの作成が失敗することがあります。その場合、SVMを削除して再度作成する必要があります。 -
MetroCluster構成用のSVMが、1GBのルート ボリュームで作成されます。同期元SVMの状態は「running」、同期先SVMの状態は「stopped」になります。
スイッチバック時の動作
ディザスタ サイトがリカバリーし、アグリゲートが修復されると、MetroClusterのスイッチバック処理によって、ストレージ アクセスとクライアント アクセスがディザスタ リカバリー サイトからホーム クラスタに戻ります。
metrocluster switchbackコマンドは、プライマリー サイトを通常の完全なMetroCluster状態に戻します。設定に対する変更があった場合、元のSVMに反映されます。次に、データ サーバー処理がディザスタ サイトの同期元SVMに返され、サバイバー サイトで動作していた同期先SVMは非アクティブになります。
MetroCluster構成がスイッチオーバー状態のときにサバイバー サイトでSVMが削除された場合、スイッチバック プロセスで次の処理が実行されます。
-
パートナー サイト(元のディザスタ サイト)の対応するSVMを削除する
-
削除されたSVMにピアリング関係がある場合は削除する