
![]()
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
MetroCluster マニュアル ( CA08871-401 )
MetroCluster構成でONTAPを使用する場合の考慮事項
MetroCluster構成でONTAPを使用する場合は、ライセンス、MetroCluster構成の外部にあるクラスタとのピアリング、ボリューム処理やNVFAIL処理などのONTAP処理の実行について、一定の考慮事項に注意する必要があります。
2つのクラスタからなるONTAP構成は、ネットワークも含めて両者が同じである必要があります。これは、MetroClusterの機能では、スイッチオーバーが実行される際に、クラスタがパートナーにデータをシームレスに提供できることが求められるからです。
ライセンスに関する考慮事項
-
両方のサイトに同じサイト ライセンスが設定されている必要があります。
-
すべてのノードに同じノード ロック式ライセンスが設定されている必要があります。
SnapMirrorに関する考慮事項
-
SnapMirror SVMディザスタ リカバリーは、MetroCluster構成でのみサポートされます。
ONTAP System ManagerでのMetroCluster処理
ONTAPのバージョンによっては、MetroCluster固有の一部の処理をONTAP System Managerを使用して実行できます。
詳細については、「ONTAP System Managerを使用したMetroClusterサイトの管理の概要」を参照してください。
MetroCluster構成でのFlexCacheのサポート
MetroCluster構成でFlexCacheボリュームがサポートされます。スイッチオーバーまたはスイッチバック処理後、手動で再ピアリングする際の要件について理解しておく必要があります。
スイッチオーバー後のSVMの再ピアリング - FlexCacheの元のSVMとキャッシュSVMが同じMetroClusterサイト内にある場合
ネゴシエートまたは計画外スイッチオーバー後、クラスタ内のすべてのSVM FlexCacheピアリング関係を手動で設定する必要があります。
例えば、SVM vs1(キャッシュ)とvs2(元)がsite_Aにあるとします。これらのSVMはピアリングされています。
スイッチオーバー後、パートナー サイト(site_B)でSVM vs1-mcとvs2-mcがアクティブになります。FlexCacheが機能するためには、これらのSVMをvserver peer repeerコマンドを使用して手動で再ピアリングする必要があります。
スイッチオーバーまたはスイッチバック後のSVMの再ピアリング - FlexCacheデスティネーションSVMが第3のクラスタにあり切断モードになっている場合
MetroCluster構成外のクラスタとのFlexCache関係で、スイッチオーバー時に関連するクラスタが切断モードであった場合は、スイッチオーバー後に必ずピアリングを手動で再設定する必要があります。
次に例を示します。
-
FlexCacheの一方(vs1のcache_1)がMetroCluster構成のsite_Aにある
-
FlexCacheのもう一方(vs2のorigin_1)がMetroCluster構成外のsite_Cにある
スイッチオーバー実行時にsite_Aとsite_Cが接続されていなかった場合、スイッチオーバー後にsite_B(スイッチオーバー クラスタ)とsite_CのSVMをvserver peer repeerコマンドを使用して手動で再ピアリングする必要があります。
スイッチバックが実行されたら、今度はsite_A(元のクラスタ)とsite_CのSVMを再ピアリングする必要があります。
MetroCluster構成でのFabricPoolのサポート
MetroCluster構成でFabricPoolストレージ階層がサポートされます。
FabricPoolの使用に関する一般的な情報については、「ディスクとローカル階層(アグリゲート)の概要」を参照してください。
FabricPool使用時の考慮事項
-
各クラスタに同じ容量制限のFabricPoolライセンスが必要です。
-
各クラスタに同じ名前のIPspaceが必要です。
これには、デフォルトのIPspaceか管理者が作成したIPspaceを使用できます。このIPspaceは、FabricPoolオブジェクト ストア設定のセットアップに使用されます。
-
選択したIPspaceについて、各クラスタで外部のオブジェクト ストアにアクセスできるクラスタ間LIFが定義されている必要があります。
ミラーリングされたFabricPoolで使用するアグリゲートの設定
| アグリゲートを設定する前に、「ディスクおよびアグリゲートの管理」の「MetroCluster構成でのFabricPoolのオブジェクト ストアのセットアップ」の説明に従ってオブジェクト ストアを設定する必要があります。 |
FabricPoolで使用するアグリゲートを設定するには、次の手順を実行します。
-
アグリゲートを作成するか、既存のアグリゲートを選択します。
-
アグリゲートをMetroCluster構成内の標準のミラー アグリゲートとしてミラーリングします。
-
「ディスクおよびアグリゲートの管理」の説明に従って、アグリゲートを使用してFabricPoolミラーを作成します。
-
プライマリー オブジェクト ストアを接続します。
これは、クラスタに物理的に近いオブジェクト ストアです。
-
ミラー オブジェクト ストアを追加します。
これは、プライマリー オブジェクト ストアよりもクラスタから物理的に離れているオブジェクト ストアです。
-
MetroCluster構成でのFlexGroupのサポート
MetroCluster構成でFlexGroupボリュームがサポートされます。
MetroCluster構成のジョブ スケジュール
ユーザーが作成したジョブ スケジュールがMetroCluster構成のクラスタ間で自動的にレプリケートされます。クラスタでジョブ スケジュールを作成、変更、または削除すると、Configuration Replication Service(CRS)を使用して同じスケジュールがパートナー クラスタに自動的に作成されます。
| システムによって作成されたスケジュールはレプリケートされません。両方のクラスタのジョブ スケジュールが同じになるように、パートナー クラスタで同じ操作を手動で実行する必要があります。 |
MetroClusterサイトから第3のクラスタへのクラスタ ピアリング
ピアリング設定はレプリケートされないため、MetroCluster構成のどちらかのクラスタを構成外の第3のクラスタにピアリングする場合は、パートナーのMetroClusterクラスタでもピアリングを設定する必要があります。これにより、スイッチオーバーが発生した場合もピアリングが維持されます。
MetroCluster外のクラスタではONTAP 9.7以降を実行している必要があります。そうでない場合、両方のMetroClusterパートナーでピアリングが設定されていても、スイッチオーバーが発生するとピアリングが失われます。
MetroCluster構成でのLDAPクライアント設定のレプリケーション
ローカル クラスタのStorage Virtual Machine(SVM)に作成されたLDAPクライアント設定は、リモート クラスタのパートナーのデータSVMにレプリケートされます。例えば、ローカル クラスタの管理SVMにLDAPクライアント設定が作成されると、リモート クラスタのすべての管理データSVMにレプリケートされます。このMetroCluster機能は、リモート クラスタのすべてのパートナーSVMでLDAPクライアント設定をアクティブにするためのものです。
MetroCluster構成用のネットワーク設定およびLIF作成ガイドライン
MetroCluster構成でLIFがどのように作成およびレプリケートされるかを理解しておく必要があります。また、ネットワーク設定時に適切に判断できるように、どういった整合性が必要とされるかも把握しておく必要があります。
IPspaceオブジェクトのレプリケーションとサブネットの設定の要件
パートナー クラスタにIPspaceオブジェクトをレプリケートするための要件、およびMetroCluster構成でサブネットとIPv6を設定するための要件を理解しておく必要があります。
IPspaceレプリケーション
IPspaceオブジェクトをパートナー クラスタにレプリケートするときは、次のガイドラインを考慮する必要があります。
-
2つのサイトのIPspace名が一致している必要があります。
-
IPspaceオブジェクトは手動でパートナー クラスタにレプリケートする必要があります。
IPspaceをレプリケートする前に作成されてIPspaceに割り当てられたStorage Virtual Machine(SVM)は、パートナー クラスタにレプリケートされません。
サブネット設定
MetroCluster構成でサブネットを設定するときは、次のガイドラインを考慮する必要があります。
-
MetroCluster構成の両方のクラスタのサブネットが同じIPspaceにあり、サブネット名、サブネット、ブロードキャスト ドメイン、ゲートウェイが同じである必要があります。
-
2つのクラスタのIP spaceが違う必要があります。
次の例では、IP spaceが異なります。
cluster_A::> network subnet show IPspace: Default Subnet Broadcast Avail/ Name Subnet Domain Gateway Total Ranges --------- ---------------- --------- ------------ ------- --------------- subnet1 192.168.2.0/24 Default 192.168.2.1 10/10 192.168.2.11-192.168.2.20 cluster_B::> network subnet show IPspace: Default Subnet Broadcast Avail/ Name Subnet Domain Gateway Total Ranges --------- ---------------- --------- ------------ -------- --------------- subnet1 192.168.2.0/24 Default 192.168.2.1 10/10 192.168.2.21-192.168.2.30
IPv6設定
一方のサイトでIPv6が設定されている場合は、もう一方のサイトでもIPv6を設定する必要があります。
MetroCluster構成でのLIFの作成に関する要件
MetroCluster構成でネットワークを設定するときは、LIFの作成に関する要件に注意する必要があります。
LIFを作成する際は、次のガイドラインを考慮する必要があります。
-
Fibre Channel:ストレッチVSANまたはストレッチ ファブリックを使用する必要があります。
-
IP/iSCSI:レイヤー2拡張ネットワークを使用する必要があります。
-
ARPブロードキャスト:2つのクラスタ間でARPブロードキャストを有効にする必要があります。
-
LIFの重複:同じIPspaceに同じIPアドレスを持つ複数のLIF(重複するLIF)を作成することはできません。
-
NFSおよびSAN構成:ミラーされていないアグリゲートとミラーされたアグリゲートの両方に異なるStorage Virtual Machine(SVM)を使用する必要があります。
LIFの作成の確認
MetroCluster構成内にLIFが作成されたことを確認するには、metrocluster check lif showコマンドを実行します。LIFの作成中に問題が発生した場合は、metrocluster check lif repair-placementコマンドを使用して問題を修正できます。
LIFのレプリケーションおよび配置の要件と問題
MetroCluster構成におけるLIFのレプリケーションの要件を理解しておく必要があります。また、レプリケートされたLIFがパートナー クラスタにどのように配置されるかを把握し、LIFのレプリケーションまたはLIFの配置に失敗した場合に発生する問題について確認しておく必要があります。
パートナー クラスタへのLIFのレプリケーション
MetroCluster構成内の1つのクラスタにLIFを作成すると、そのLIFはパートナー クラスタにレプリケートされます。LIFは名前に基づいて1対1で配置されるわけではありません。スイッチオーバー処理後にLIFを使用できるようにするため、LIFの配置プロセスは、ポートがLIFをホストできるかを到達可能性とポート属性チェックに基づいて検証します。
LIFをレプリケートしてパートナー クラスタに配置するには、システムが次の条件を満たしている必要があります。
条件 |
LIFタイプ:FC |
LIFタイプ:IP/iSCSI |
|---|---|---|
ノードの特定 |
LIFを作成したノードのディザスタ リカバリー(DR)パートナーに、レプリケートされたLIFが配置されます。DRパートナーが使用できない場合は、DR HA パートナーに配置されます。 |
LIFを作成したノードのDRパートナーに、レプリケートされたLIFが配置されます。DRパートナーが使用できない場合は、DR HA パートナーに配置されます。 |
ポートの特定 |
接続されているFCターゲット ポートがDRクラスタで特定されます。 |
ソースLIFと同じIPspaceにあるDRクラスタのポートが到達可能性チェックの対象として選択されます。DRクラスタに同じIPspaceのポートがない場合はLIFを配置できません。 同じIPspaceとサブネットですでにLIFをホストしているDRクラスタのポートは自動的に到達可能とマークされ、配置先として使用できます。これらのポートは、到達可能性チェックの対象ではありません。 |
到達可能性チェック |
到達可能性は、DRクラスタのポートのソース ファブリックWWNの接続をチェックすることによって、判別されます。DRサイトに同じファブリックがない場合、LIFはDRパートナーの任意のポートに配置されます。 |
上記で特定されたDRクラスタの各ポートから配置対象LIFのソースIPアドレスにAddress Resolution Protocol(ARP)ブロードキャストが送信され、その応答に基づいて到達可能性が判別されます。到達可能性チェックにパスするには、2つのクラスタ間でARPブロードキャストが許可される必要があります。 ソースLIFから応答を受信した各ポートが配置可能なポートとしてマークされます。 |
ポートの選択 |
ONTAPにより、アダプター タイプや速度などの属性に基づいてポートが分類され、属性が一致するポートが選択されます。属性が一致するポートがない場合、LIFはDRパートナーの任意の接続されたポートに配置されます。 |
到達可能性チェックで到達可能とマークされたポートのうち、LIFのサブネットに関連付けられたブロードキャスト ドメイン内のポートが優先して選択されます。DRクラスタにLIFのサブネットに関連付けられたブロードキャスト ドメイン内の使用可能なネットワーク ポートがない場合は、ソースLIFに到達可能なポートが選択されます。 ソースLIFに到達可能なポートがない場合は、ソースLIFのサブネットに関連付けられたブロードキャスト ドメインからポートが選択されます。該当するブロードキャスト ドメインが存在しない場合は、任意のポート選択されます。 アダプター タイプ、インターフェイス タイプ、速度などの属性に基づいてポートが分類され、属性が一致するポートが選択されます。 |
LIFの配置 |
到達可能なポートのうち、最も負荷の少ないポートが配置先として選択されます。 |
選択されたポートのうち、最も負荷の少ないポートが配置先として選択されます。 |
DRパートナー停止時のレプリケートされたLIFの配置
あるノードにiSCSIまたはFC LIFが作成され、そのノードのDRパートナーがテイクオーバーされた場合、LIFがレプリケートされてDR HA パートナー ノードに配置されます。その後ギブバック処理が発生しても、LIFはDRパートナーに自動的には移動されません。そのため、パートナー クラスタ内の1つのノードにLIFが集中する可能性があります。MetroClusterのスイッチオーバー処理が発生した場合、その後のStorage Virtual Machine(SVM)に属するLUNをマップする処理は失敗します。
テイクオーバー処理またはギブバック処理の完了後、metrocluster check lif showコマンドを実行してLIFの配置が正しいことを確認する必要があります。エラーがある場合は、metrocluster check lif repair-placementコマンドを実行して問題を解決します。
LIF配置エラー
metrocluster check lif showコマンドで表示されるLIF配置エラーは、スイッチオーバー処理のあとも削除されません。配置エラーがあるLIFに対してnetwork interface modify、network interface rename、またはnetwork interface deleteのいずれかのコマンドを実行すると、エラーが削除され、metrocluster check lif showコマンドの出力に表示されなくなります。
LIFレプリケーション エラー
metrocluster check lif showコマンドを使用して、LIFのレプリケーションが成功したかを確認することもできます。LIFのレプリケーションが失敗すると、EMSメッセージが表示されます。
レプリケーションの問題を修正するには、正しいポートが見つからなかったLIFに対してmetrocluster check lif repair-placementコマンドを実行します。MetroClusterスイッチオーバー処理の際に確実にLIFを使用できるよう、LIFのレプリケーション エラーはできるだけ早く解決する必要があります。
| ソースSVMがダウンしている場合でも、デスティネーションSVMで同じIPspaceとネットワークを使用するポートに別のSVMに所属するLIFが設定されていれば、LIFの配置は続行されます。 |
ルート アグリゲートでのボリューム作成
MetroCluster構成内のノードのルート アグリゲート(HAポリシーがCFOのアグリゲート)に新しいボリュームを作成することはできません。
この制限があるため、ルート アグリゲートをvserver add-aggregatesコマンドでSVMに追加することはできません。
MetroCluster構成でのSVMディザスタ リカバリー
MetroCluster構成のアクティブなStorage Virtual Machine(SVM)をSnapMirror SVMディザスタ リカバリー機能でソースとして使用できます。デスティネーションSVMは、MetroCluster構成外の第3のクラスタに配置する必要があります。
ONTAP 9.11.1以降では、下の図に示すように、MetroCluster構成内の両方のサイトを、ETERNUS HXまたはETERNUS AXデスティネーション クラスタとのSVM DR関係のソースにすることができます。
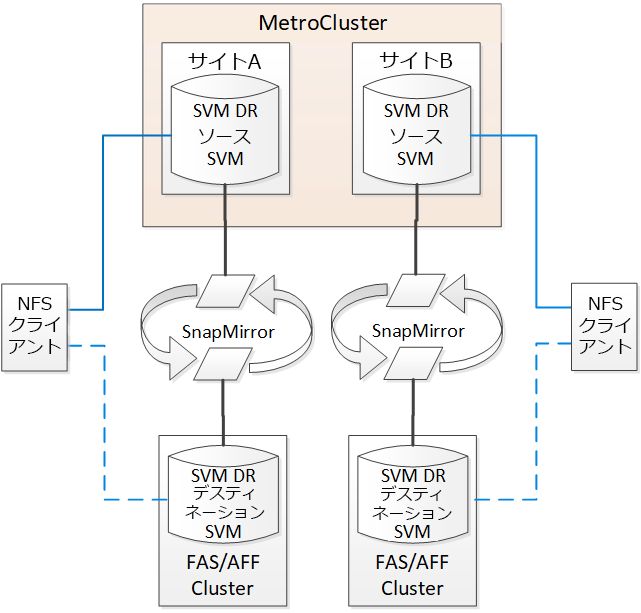
SVMをSnapMirrorディザスタ リカバリーで使用する場合は、次の要件と制限に注意してください。
-
SVMディザスタ リカバリー関係のソースとして使用できるのは、MetroCluster構成のアクティブなSVMだけです。
スイッチオーバー前の同期元のSVMとスイッチオーバー後の同期先のSVMのどちらもソースに使用できます。
-
MetroCluster構成が安定した状態のときはMetroClusterの同期先のSVMはオンラインでないため、同期先ボリュームをSVMディザスタ リカバリー関係のソースにすることはできません。
次の図は、安定した状態のときのSVMディザスタ リカバリーの動作を示しています。
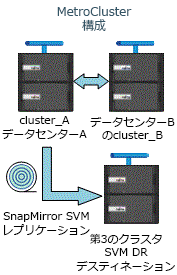
-
SVM DR関係のソースが同期元のSVMの場合、ソースのSVM DR関係情報がMetroClusterパートナーにレプリケートされます。
これにより、次の図に示すように、スイッチオーバー後もSVM DRの更新を継続できます。
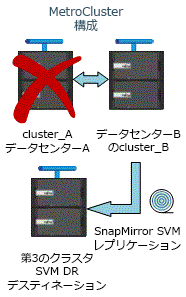
-
スイッチオーバーおよびスイッチバックの実行中に、SVM DRのデスティネーションへのレプリケーションが失敗することがあります。
ただし、スイッチオーバーまたはスイッチバック処理の完了後、SVM DRの次回のスケジュールされている更新は成功します。
SVM DR関係の設定の詳細については、データ保護の「SVM構成をレプリケートする」を参照してください。
ディザスタ リカバリー サイトでのSVMの再同期
再同期では、MetroCluster構成のディザスタ リカバリー(DR)ソースであるStorage Virtual Machine(SVM)がMetroClusterでないサイトのデスティネーションSVMからリストアされます。
再同期中は、次の図に示すように、ソースSVM(cluster_A)が一時的にデスティネーションSVMとして機能します。
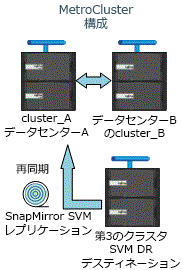
再同期中に計画外スイッチオーバーが発生した場合
再同期中に計画外スイッチオーバーが発生すると、再同期の転送が停止します。計画外スイッチオーバーが発生した場合は次のようになります。
-
MetroClusterサイトのデスティネーションSVM(再同期前のソースSVM)は、デスティネーションSVMのままです。パートナー クラスタのSVMは、同じサブタイプで非アクティブのままです。
-
同期先のSVMをデスティネーションとして、SnapMirror関係を手動で再作成する必要があります。
-
スイッチオーバー後、SnapMirror作成処理を実行しないかぎり、サバイバー サイトでのSnapMirror showの出力にSnapMirror関係は表示されません。
再同期中に計画外スイッチオーバーが発生した場合のスイッチバックの実行
スイッチバック プロセスを正常に実行するには、再同期関係を解除して削除する必要があります。MetroCluster構成にSnapMirror DRのデスティネーションSVMがある場合、またはクラスタにサブタイプ「dp-destination」のSVMがある場合、スイッチバックは実行できません。
MetroClusterスイッチオーバー後のstorage aggregate plex showコマンド出力の未確定
MetroClusterのスイッチオーバー発生後にstorage aggregate plex showコマンドを実行すると、スイッチオーバーされたルート アグリゲートのplex0のステータスが確定していないため、「failed」と表示されます。この間、スイッチオーバーされたルートは更新されません。このプレックスの実際のステータスは、MetroClusterの修復フェーズ後に確定します。
スイッチオーバー発生時にNVFAILフラグを設定するためのボリュームの変更
MetroClusterスイッチオーバーが発生した場合にNVFAILフラグが設定されるようにボリュームを変更することができます。NVFAILフラグが設定されたボリュームは、一切変更されなくなります。コミットされた書き込みがスイッチオーバーによって失われたと想定してボリュームを処理する必要がある場合は、この変更が必要となります。
-
vol -dr-force-nvfailパラメーターをonに設定し、スイッチオーバー発生時にMetroCluster構成でNVFAILがトリガーされるようにします。vol modify -vserver vserver-name -volume volume-name -dr-force-nvfail on