
ONTAP 9.14
Introduction and concepts
ONTAP concepts
Volumes, qtrees, files, and LUNs
Storage virtualization
Replication
SnapMirror disaster recovery and data transfer
Storage Efficiency
Set up, upgrade and revert ONTAP
Set up ONTAP
Set up a cluster with ONTAP System Manager
Set up a cluster with the CLI
Create the cluster on the first node
Join remaining nodes to the cluster
Convert management LIFs from IPv4 to IPv6
Check your cluster with Active IQ Config Advisor
Synchronize the system time across the cluster
Commands for managing symmetric authentication on NTP servers
Upgrade ONTAP
Prepare for an ONTAP upgrade
How do I get and install the upgrade software image?
Which upgrade method should I use?
What should I do after my upgrade?
Overview of post-upgrade verifications
Firmware and system updates
Revert ONTAP
What should I verify before I revert?
What else should I check before I revert?
SnapMirror
How do I get and install the revert software image?
What should I do after reverting my cluster?
Verify cluster and storage health
Enable automatic switchover for MetroCluster configurations
Enable and revert LIFs to home ports
Cluster administration
Cluster management with ONTAP System Manager
Use ONTAP System Manager to access a Cluster
Download a cluster configuration
Manage maximum capacity limit of a storage VM
Monitor capacity with ONTAP System Manager
Manage AutoSupport with ONTAP System Manager
Cluster management with the CLI
Cluster and SVM administrators
Manage access to ONTAP System Manager
Access the cluster by using the CLI (cluster administrators only)
Access the cluster by using the serial port
Access the cluster by using SSH
Enable Telnet or RSH access to the cluster
Use the ONTAP command-line interface
About the different shells for CLI commands (cluster administrators only)
Methods of navigating CLI command directories
Rules for specifying values in the CLI
Methods of viewing command history and reissuing commands
Keyboard shortcuts for editing CLI commands
Use of administrative privilege levels
Set the privilege level in the CLI
Set display preferences in the CLI
Methods of using query operators
Methods of using extended queries
Manage CLI sessions (cluster administrators only)
Commands for managing records of CLI sessions
Commands for managing the automatic timeout period of CLI sessions
Cluster management basics (cluster administrators only)
Display information about the nodes in a cluster
Manage nodes
Access a node’s log, core dump, and MIB files by using a web browser
Access the system console of a node
Configure the SP/BMC network
Isolate management network traffic
Considerations for the SP/BMC network configuration
Enable the SP/BMC automatic network configuration
Manage a node remotely using the SP/BMC
About the Service Processor (SP)
About the Baseboard Management Controller (BMC)
Methods of managing SP/BMC firmware updates
When the SP/BMC uses the network interface for firmware updates
Accounts that can access the SP
Access the SP/BMC from an administration host
Access the SP/BMC from the system console
Relationship among the SP CLI, SP console, and system console sessions
Manage the IP addresses that can access the SP
Use online help at the SP/BMC CLI
Commands to manage a node remotely
About the threshold-based SP sensor readings and status values of the system sensors command output
About the discrete SP sensor status values of the system sensors command output
Commands for managing the SP from ONTAP
Manage audit logging for management activities
How ONTAP implements audit logging
Changes to audit logging in ONTAP 9
Manage the banner and MOTD
Manage licenses (cluster administrators only)
Manage jobs and schedules
Back up and restore cluster configurations (cluster administrators only)
What configuration backup files are
How the node and cluster configurations are backed up automatically
Commands for managing configuration backup schedules
Commands for managing configuration backup files
Find a configuration backup file to use for recovering a node
Restore the node configuration using a configuration backup file
Find a configuration to use for recovering a cluster
Restore a cluster configuration from an existing configuration
Monitor a storage system
When and where AutoSupport messages are sent
How AutoSupport creates and sends event-triggered messages
Types of AutoSupport messages and their content
What AutoSupport subsystems are
AutoSupport size and time budgets
Files sent in event-triggered AutoSupport messages
Log files sent in AutoSupport messages
Files sent in weekly AutoSupport messages
Structure of AutoSupport messages sent by email
Requirements for using AutoSupport
Upload performance archive files
Get AutoSupport message descriptions
AutoSupport case suppression during scheduled maintenance windows
Troubleshoot AutoSupport when messages are not received
Troubleshoot AutoSupport message delivery over HTTP or HTTPS
Monitor the health of your system
Ways to respond to system health alerts
System health alert customization
How health alerts trigger AutoSupport messages and events
Available cluster health monitors
Receive system health alerts automatically
Respond to degraded system health
Example of responding to degraded system health
Configure discovery of cluster and management network switches
Verify the monitoring of cluster and management network switches
Manage web services
Manage the web protocol engine
Commands for managing the web protocol engine
Configure SAML authentication for web services
Configure access to web services
Commands for managing web services
Verify the identity of remote servers using certificates
Mutually authenticating the cluster and a KMIP server
Generate a certificate signing request for the cluster
Disk and tier (aggregate) management
Manage local tiers (aggregates)
Prepare to add a local tier (aggregate)
Local tiers (aggregates) and RAID groups
Add (create) a local tier (aggregate)
Workflow to add a local tier (aggregate)
Determine the number of disks or disk partitions required for a local tier (aggregate)
Decide which local tier (aggregate) creation method to use
Manage the use of local tiers (aggregates)
Rename a local tier (aggregate)
Set media cost of a local tier (aggregate)
Determine drive and RAID group information for a local tier (aggregate)
Assign local tiers (aggregates) to storage VMs (SVMs)
Determine which volumes reside on a local tier (aggregate)
Determine and control a volume’s space usage in a local tier (aggregate)
Determine space usage in a local tier (aggregate)
Relocate local tier (aggregate) ownership within an HA pair
Delete a local tier (aggregate)
Add capacity (disks) to a local tier (aggregate)
Workflow to add capacity to a local tier (expanding an aggregate)
Methods to create space in a local tier (aggregate)
Manage disks
How low spare warnings can help you manage your spare disks
Additional root-data partitioning management options
When you need to update the Disk Qualification Package
Disk and partition ownership
About auto-assignment of disk ownership
Display disk and partition ownership
Change auto-assignment settings for disk ownership
Manually assign ownership of disks
Manually assign ownership of partitioned disks
Set up an active-passive configuration on nodes using root-data partitioning
Set up an active-passive configuration on nodes using root-data-data partitioning
Disk sanitization
When sanitization cannot be performed
What happens if sanitization is interrupted
Tips for managing local tiers (aggregates) containing data to be sanitized
Manage RAID configurations
Default RAID policies for local tiers (aggregates)
RAID protection levels for disks
Drive and RAID group information for a local tier (aggregate)
Convert from RAID-DP to RAID-TEC
Manage Flash Pool local tiers (aggregates)
Flash Pool local tier (aggregate) caching policies
Manage Flash Pool caching policies
Determine whether to modify the caching policy of Flash Pool local tiers (aggregates)
Modify caching policies of Flash Pool local tiers (aggregates)
Set the cache-retention policy for Flash Pool local tiers (aggregates)
Flash Pool SSD partitioning for Flash Pool local tiers (aggregates) using storage pools
Flash Pool candidacy and optimal cache size
Create a Flash Pool local tier (aggregate) using physical SSDs
Create a Flash Pool local tier (aggregate) using SSD storage pools
Determine whether a Flash Pool local tier (aggregate) is using an SSD storage pool
Add cache by adding an SSD storage pool
Create a Flash Pool using SSD storage pool allocation units
Determine the impact to cache size of adding SSDs to an SSD storage pool
FabricPool tier management
Benefits of storage tiers by using FabricPool
Considerations and requirements for using FabricPool
About FabricPool tiering policies
FabricPool management workflow
Configure FabricPool
Prepare for FabricPool configuration
Install a CA certificate if you use ONTAP S3
Set up an object store as the cloud tier for FabricPool
Set up ONTAP S3 as the cloud tier
Set up Amazon S3 as the cloud tier
Set up Google Cloud Storage as the cloud tier
Set up Azure Blob Storage for the cloud as the cloud tier
Set up object stores for FabricPool in a MetroCluster configuration
Test object store throughput performance before attaching to a local tier
Manage FabricPool
Determinine how much data in a volume is inactive by using inactive data reporting
Manage volumes for FabricPool
Create a volume for FabricPool
Object tagging using user-created custom tags
Assign a new tag during volume creation
Monitor the space utilization for FabricPool
Manage storage tiering by modifying a volume’s tiering policy or tiering minimum cooling period
Use cloud migration controls to override a volume’s default tiering policy
SVM data mobility
Volume administration
Volume and LUN management with ONTAP System Manager
Balance loads by moving volumes to another tier
Logical storage management with the CLI
Create and manage volumes
Enable large volume and large file support
SAN volumes
Configure volume provisioning options
Determine space usage in a volume or aggregate
Delete Snapshot copies automatically
Configure volumes to automatically provide more space when they are full
Configure volumes to automatically grow and shrink their size
Requirements for enabling both autoshrink and automatic Snapshot copy deletion
How the autoshrink functionality interacts with Snapshot copy deletion
Address FlexVol volume fullness and overallocation alerts
Control and monitoring I/O performance to FlexVol volumes by using Storage QoS
Protection against accidental volume deletion
Delete directories
Move and copy volumes
How moving a FlexVol volume works
Considerations and recommendations when moving volumes
Use FlexClone volumes to create efficient copies of your FlexVol volumes
Split a FlexClone volume from its parent volume
Determine the space used by a FlexClone volume
Considerations for creating a FlexClone volume from a SnapMirror source or destination volume
Use FlexClone files and FlexClone LUNs to create efficient copies of files and LUNs
Create a FlexClone file or FlexClone LUN
View node capacity for creating and deleting FlexClone files and FlexClone LUNs
View the space savings due to FlexClone files and FlexClone LUNs
Methods to delete FlexClone files and FlexClone LUNs
How a FlexVol volume can reclaim free space with autodelete setting
Configure a FlexVol volume to automatically delete FlexClone files and FlexClone LUNs
Prevent a specific FlexClone file or FlexClone LUN from being automatically deleted
Use qtrees to partition your FlexVol volumes
Convert a directory to a qtree
Logical space reporting and enforcement for volumes
What logical space reporting shows
What logical space enforcement does
Use quotas to restrict or track resource usage
Overview of the quota process
Differences among hard, soft, and threshold quotas
What quota rules, quota policies, and quotas are
Special kinds of quotas
Considerations for assigning quota policies
How quotas work with users and groups
How you specify UNIX users for quotas
How you specify Windows users for quotas
How default user and group quotas create derived quotas
How quotas are applied to the root user
How quotas work with special Windows groups
How quotas are applied to users with multiple IDs
How ONTAP determines user IDs in a mixed environment
How tree quotas work
How user and group quotas work with qtrees
How default tree quotas on a FlexVol volume create derived tree quotas
How default user quotas on a FlexVol volume affect quotas for the qtrees in that volume
How qtree changes affect quotas
How deleting a qtree affects tree quotas
How renaming a qtree affects quotas
How changing the security style of a qtree affects user quotas
How quotas are activated
How you can view quota information
How you can use the quota report to see what quotas are in effect
Why enforced quotas differ from configured quotas
Use the quota report to determine which quotas limit writes to a specific file
Commands for displaying information about quotas
When to use the volume quota policy rule show and volume quota report commands
Difference in space usage displayed by a quota report and a UNIX client
How the ls command accounts for space usage
Modify (or Resizing) quota limits
Reinitialize quotas after making extensive changes
Use deduplication, data compression, and data compaction to increase storage efficiency
Enable deduplication on a volume
Disable deduplication on a volume
Manage automatic volume-level background deduplication on ETERNUS AX series
Manage aggregate-level inline deduplication on ETERNUS AX series
Manage aggregate-level background deduplication on ETERNUS AX series
Temperature-sensitive storage efficiency overview
Storage efficiency behavior with volume move and SnapMirror
Change volume inactive data compression threshold
View volume footprint savings with or without temperature-sensitive storage efficiency
Enable data compression on a volume
Move between secondary compression and adaptive compression
Disable data compression on a volume
Manage inline data compaction for ETERNUS AX series
Enable inline data compaction for ETERNUS HX series
Inline storage efficiency enabled by default on ETERNUS AX series
Enable storage efficiency visualization
Create a volume efficiency policy to run efficiency operations
Assign a volume efficiency policy to a volume
Modify a volume efficiency policy
View a volume efficiency policy
Manage volume efficiency operations manually
Run efficiency operations manually
Use checkpoints to resume efficiency operation
Manage volume efficiency operations using schedules
Run efficiency operations depending on the amount of new data written
Monitor volume efficiency operations
Rehost a volume from one SVM to another SVM
Recommended volume and file or LUN configuration combinations
Determine the correct volume and LUN configuration combination for your environment
Configuration settings for space-reserved files or LUNs with thick-provisioned volumes
Configuration settings for non-space-reserved files or LUNs with thin-provisioned volumes
Configuration settings for space-reserved files or LUNs with semi-thick volume provisioning
Cautions and considerations for changing file or directory capacity
Considerations for changing the maximum number of files allowed on a FlexVol volume
Cautions for increasing the maximum directory size for FlexVol volumes
Features supported with FlexClone files and FlexClone LUNs
How deduplication works with FlexClone files and FlexClone LUNs
How Snapshot copies work with FlexClone files and FlexClone LUNs
How access control lists work with FlexClone files and FlexClone LUNs
How quotas work with FlexClone files and FlexClone LUNs
How FlexClone volumes work with FlexClone files and FlexClone LUNs
How NDMP works with FlexClone files and FlexClone LUNs
How volume SnapMirror works with FlexClone files and FlexClone LUNs
How volume move affects FlexClone files and FlexClone LUNs
How space reservation works with FlexClone files and FlexClone LUNs
How an HA configuration works with FlexClone files and FlexClone LUNs
Provision NAS storage for large file systems using FlexGroup volumes
FlexGroup volumes management with the CLI
Supported and unsupported configurations for FlexGroup volumes
FlexGroup volume setup
Enable 64-bit NFSv3 identifiers on an SVM
Manage FlexGroup volumes
Monitor the space usage of a FlexGroup volume
Increase the size of a FlexGroup volume
Reduce the size of a FlexGroup volume
Configure FlexGroup volumes to automatically grow and shrink their size
Delete directories rapidly on a cluster
Manage client rights to delete directories rapidly
Create qtrees with FlexGroup volumes
Use quotas for FlexGroup volumes
Enable storage efficiency on a FlexGroup volume
Protect FlexGroup volumes using Snapshot copies
Move the constituents of a FlexGroup volume
Data protection for FlexGroup volumes
Create a SnapMirror relationship for FlexGroup volumes
Create a SnapVault relationship for FlexGroup volumes
Create a unified data protection relationship for FlexGroup volumes
Create an SVM disaster recovery relationship for FlexGroup volumes
Transition an existing FlexGroup SnapMirror relationship to SVM DR
Convert a FlexVol volume to a FlexGroup volume within an SVM-DR relationship
Considerations for creating SnapMirror cascade and fanout relationships for FlexGroups
Manage data protection operations for FlexGroup volumes
Disaster recovery for FlexGroup volumes
Activate the destination FlexGroup volume
Reactivate the original source FlexGroup volume after disaster
Reverse a SnapMirror relationship between FlexGroup volumes during disaster recovery
Expand FlexGroup volumes in a SnapMirror relationship
Expand the source FlexGroup volume of a SnapMirror relationship
Expand the destination FlexGroup volume of a SnapMirror relationship
Perform a SnapMirror single file restore from a FlexGroup volume
Restore a FlexGroup volume from a SnapVault backup
Convert FlexVol volumes to FlexGroup volumes
Convert a FlexVol volume to a FlexGroup volume
Convert a FlexVol volume SnapMirror relationship to a FlexGroup volume SnapMirror relationship
FlexCache volumes management
FlexCache volumes supported protocols and features
Network management
Manage your network with ONTAP System Manager
Set up NAS path failover with the CLI
ONTAP 9.8 and later
Manage your network with the CLI
Upgrade considerations
Verify your networking configuration after upgrading to ONTAP 9.8 or later
Networking components of a cluster
Relationship between broadcast domains, failover groups, and failover policies
Configure network ports (cluster administrators only)
Combine physical ports to create interface groups
Configure VLANs over physical ports
Modify network port attributes
Modify MTU setting for interface group ports
Monitor the health of network ports
Monitor the reachability of network ports in ONTAP 9.8 and later
Convert 40GbE NIC ports into multiple 10GbE ports for 10GbE connectivity
Configure IPspaces (cluster administrators only)
Configure broadcast domains (cluster administrators only)
ONTAP 9.8 and later
About broadcast domains for ONTAP 9.8 and later
Example of using broadcast domains
Add or remove ports from a broadcast domain
Configure failover groups and policies for LIFs
Configure subnets (cluster administrators only)
Configure LIFs (cluster administrators only)
LIF compatibility with port types
Configure LIF service policies
ONTAP 9.8 or later-Recover from an incorrectly configured cluster LIF
Configure host-name resolution
Balance network loads to optimize user traffic (cluster administrators only)
Secure your network
Configure network security using Federal Information Processing Standards (FIPS)
Configure IP security (IPsec) over wire encryption
Configure QoS marking (cluster administrators only)
Manage SNMP on the cluster (cluster administrators only)
Create an SNMP community and assign it to a LIF
Configure SNMPv3 users in a cluster
Manage routing in an SVM
View network information
Display network port information
Display information about a VLAN (cluster administrators only)
Display interface group information (cluster administrators only)
Display DNS host table entries (cluster administrators only)
Display DNS domain configurations
Display information about failover groups
Display LIFs in a load balancing zone
Commands for diagnosing network problems
Display network connectivity with neighbor discovery protocols
NAS storage management
Manage NAS protocols with ONTAP System Manager
Secure client access with Kerberos
Provide client access with name services
Configure NFS with the CLI
Preparation
Assess physical storage requirements
Assess networking requirements
Configure NFS access to an SVM
Verify that the NFS protocol is enabled on the SVM
Open the export policy of the SVM root volume
Enable DNS for host-name resolution
Configure name services
Configure the name service switch table
Configure local UNIX users and groups
Load local UNIX users from a URI
Use Kerberos with NFS for strong security
Verify permissions for Kerberos configuration
Create an NFS Kerberos realm configuration
Add storage capacity to an NFS-enabled SVM
Add a rule to an export policy
Secure NFS access using export policies
Manage the processing order of export rules
Manage NFS with the CLI
Understand NAS file access
How ONTAP controls access to files
How ONTAP handles NFS client authentication
Create and manage data volumes in NAS namespaces
Create data volumes with specified junction points
Creating data volumes without specifying junction points
Mounting or unmounting existing volumes in the NAS namespace
Configure security styles
How security styles affect data access
What the security styles and their effects are
Where and when to set security styles
Decide which security style to use on SVMs
How security style inheritance works
Configure security styles on SVM root volumes
Set up file access using NFS
Secure NFS access using export policies
How export policies control client access to volumes or qtrees
Default export policy for SVMs
Manage clients with an unlisted security type
How security types determine client access levels
Manage superuser access requests
How ONTAP uses export policy caches
How access cache parameters work
Removing an export policy from a qtree
Validating qtree IDs for qtree file operations
Export policy restrictions and nested junctions for FlexVol volumes
Using Kerberos with NFS for strong security
Configure name services
Configure name mappings
Multidomain searches for UNIX user to Windows user name mappings
Manage file access using NFS
Controlling NFS access over TCP and UDP
Controlling NFS requests from nonreserved ports
Handling NFS access to NTFS volumes or qtrees for unknown UNIX users
Considerations for clients that mount NFS exports using a nonreserved port
Performing stricter access checking for netgroups by verifying domains
Modifying ports used for NFSv3 services
Commands for managing NFS servers
Troubleshooting name service issues
Verifying name service connections
Commands for managing name service switch entries
Commands for managing name service cache
Commands for managing name mappings
Commands for managing local UNIX users
Commands for managing local UNIX groups
Limits for local UNIX users, groups, and group members
Manage limits for local UNIX users and groups
Commands for managing local netgroups
Commands for managing NIS domain configurations
Commands for managing LDAP client configurations
Commands for managing LDAP configurations
Commands for managing LDAP client schema templates
Commands for managing NFS Kerberos interface configurations
Commands for managing NFS Kerberos realm configurations
Commands for managing export policies
Commands for managing export rules
Configure the NFS credential cache
Manage export policy caches
Display the export policy netgroup queue and cache
Checking whether a client IP address is a member of a netgroup
Manage file locks
About file locking between protocols
How ONTAP treats read-only bits
How ONTAP differs from Windows on handling locks on share path components
How FPolicy first-read and first-write filters work with NFS
Modifying the NFSv4.1 server implementation ID
Manage NFSv4 ACLs
Benefits of enabling NFSv4 ACLs
Enable or disable modification of NFSv4 ACLs
How ONTAP uses NFSv4 ACLs to determine whether it can delete a file
Manage NFSv4 file delegations
Configure NFSv4 file and record locking
About NFSv4 file and record locking
Enable or disable NFSv4 referrals
Support for VMware vStorage over NFS
Enable or disable VMware vStorage over NFS
Enable or disable rquota support
NFSv3 and NFSv4 performance improvement by modifying the TCP transfer size
Modifying the NFSv3 and NFSv4 TCP maximum transfer size
Supported NFS versions and clients
NFSv4.0 functionality supported by ONTAP
Limitations of ONTAP support for NFSv4
NFS and SMB file and directory naming dependencies
Characters a file or directory name can use
Case-sensitivity of file and directory names in a multiprotocol environment
How ONTAP creates file and directory names
How ONTAP handles multi-byte file, directory, and qtree names
Configure character mapping for SMB file name translation on volumes
Commands for managing character mappings for SMB file name translation
Manage NFS trunking
Configure a new NFS server and exports for trunking
Create a trunking-enabled NFS server
Adapt existing NFS exports for trunking
Adapting single-path exports overview
Enable trunking on an NFS server
Update your network for trunking
Configure SMB with the CLI
Preparation
Assess physical storage requirements
Assess networking requirements
Configure SMB access to an SVM
Verify that the SMB protocol is enabled on the SVM
Open the export policy of the SVM root volume
Enable DNS for host-name resolution
Set up an SMB server in an Active Directory domain
Commands for managing symmetric authentication on NTP servers
Set up an SMB server in a workgroup
Configure SMB client access to shared storage
Requirements and considerations for creating an SMB share
Create SMB share access control lists
Manage SMB with the CLI
SMB server support
Supported SMB versions and functionality
Manage SMB servers
Use options to customize SMB servers
Configure the grant UNIX group permission to SMB users
Configure access restrictions for anonymous users
Manage how file security is presented to SMB clients for UNIX security-style data
Enable or disable the presentation of NTFS ACLs for UNIX security-style data
Manage SMB server security settings
How ONTAP handles SMB client authentication
Guidelines for SMB server security settings in an SVM disaster recovery configuration
Display information about CIFS server security settings
Enable or disable required password complexity for local SMB users
Modify the CIFS server Kerberos security settings
Set the CIFS server minimum authentication security level
Configure strong security for Kerberos-based communication by using AES encryption
Enable or disable AES encryption for Kerberos-based communication
Use SMB signing to enhance network security
How SMB signing policies affect communication with a CIFS server
Performance impact of SMB signing
Recommendations for configuring SMB signing
Guidelines for SMB signing when multiple data LIFS are configured
Enable or disable required SMB signing for incoming SMB traffic
Configure required SMB encryption on SMB servers for data transfers over SMB
Performance impact of SMB encryption
Enable or disable required SMB encryption for incoming SMB traffic
Determine whether clients are connected using encrypted SMB sessions
Secure LDAP session communication
Configure SMB Multichannel for performance and redundancy
Configure default Windows user to UNIX user mappings on the SMB server
Display information about what types of users are connected over SMB sessions
Command options to limit excessive Windows client resource consumption
Improve client performance with traditional and lease oplocks
Write cache data-loss considerations when using oplocks
Enable or disable oplocks when creating SMB shares
Commands for enabling or disabling oplocks on volumes and qtrees
Apply Group Policy Objects to SMB servers
Requirements for using GPOs with your CIFS server
Enable or disable GPO support on a SMB server
Manually updating GPO settings on the CIFS server
Display information about GPO configurations
Display detailed information about restricted group GPOs
Commands for managing CIFS servers computer account passwords
Manage domain controller connections
Display information about discovered servers
Manage domain controller discovery
Add preferred domain controllers
Commands for managing preferred domain controllers
Use null sessions to access storage in non-Kerberos environments
Manage NetBIOS aliases for SMB servers
Add a list of NetBIOS aliases to the CIFS server
Remove NetBIOS aliases from the NetBIOS alias list
Display the list of NetBIOS aliases on CIFS servers
Determine whether SMB clients are connected using NetBIOS aliases
Manage miscellaneous SMB server tasks
Move CIFS servers to different OUs
Modify the dynamic DNS domain on the SVM before moving the SMB server
Join anSVM to an Active Directory domain
Display information about NetBIOS over TCP connections
Use IPv6 for SMB access and SMB services
Support for IPv6 with SMB access and CIFS services
How CIFS servers use IPv6 to connect to external servers
Set up file access using SMB
Configure security styles
How security styles affect data access
What the security styles and their effects are
Where and when to set security styles
Decide which security style to use on SVMs
How security style inheritance works
Configure security styles on SVM root volumes
Create and manage data volumes in NAS namespaces
Create data volumes with specified junction points
Create data volumes without specifying junction points
Configure name mappings
Multidomain searches for UNIX user to Windows user name mappings
Configure multidomain name-mapping searches
Enable or disable multidomain name mapping searches
Reset and rediscover trusted domains
Display information about discovered trusted domains
Add, remove, or replace trusted domains in preferred trusted domain lists
Create and configure SMB shares
What the default administrative shares are
Directory case-sensitivity requirements when creating shares in a multiprotocol environment
Optimize SMB user access with the force-group share setting
Create an SMB share with the force-group share setting
Secure file access by using SMB share ACLs
Guidelines for managing SMB share-level ACLs
Secure file access by using file permissions
Configure advanced NTFS file permissions using the Windows Security tab
Configure NTFS file permissions using the ONTAP CLI
How UNIX file permissions provide access control when accessing files over SMB
Secure file access by using Dynamic Access Control (DAC)
Supported Dynamic Access Control functionality
Considerations when using Dynamic Access Control and central access policies with CIFS servers
Enable or disable Dynamic Access Control
Manage ACLs that contain Dynamic Access Control ACEs when Dynamic Access Control is disabled
Configure central access policies to secure data on CIFS servers
Display information about Dynamic Access Control security
Secure SMB access using export policies
How export policies are used with SMB access
Examples of export policy rules that restrict or allow access over SMB
Secure file access by using Storage-Level Access Guard
Use cases for using Storage-Level Access Guard
Workflow to configure Storage-Level Access Guard
Configure Storage-Level Access Guard
Manage file access using SMB
Use local users and groups for authentication and authorization
How ONTAP uses local users and groups
Local users and groups concepts
Reasons for creating local users and local groups
How local user authentication works
How user access tokens are constructed
Guidelines for using SnapMirror on SVMs that contain local groups
What happens to local users and groups when deleting CIFS servers
How you can use Microsoft Management Console with local users and groups
Guidelines for using BUILTIN groups and the local administrator account
Requirements for local user passwords
Predefined BUILTIN groups and default privileges
Enable or disable local users and groups functionality
Manage local user accounts
Enable or disable local user accounts
Change local user account passwords
Display information about local users
Configure bypass traverse checking
Allow users or groups to bypass directory traverse checking
Disallow users or groups from bypassing directory traverse checking
Display information about file security and audit policies
Display information about file security on NTFS security-style volumes
Display information about file security on mixed security-style volumes
Display information about file security on UNIX security-style volumes
Display information about NTFS audit policies on FlexVol volumes using the CLI
Display information about NFSv4 audit policies on FlexVol volumes using the CLI
Ways to display information about file security and audit policies
Manage NTFS file security, NTFS audit policies, and Storage-Level Access Guard on SVMs using the CLI
Use cases for using the CLI to set file and folder security
Limits when using the CLI to set file and folder security
How security descriptors are used to apply file and folder security
Configure and apply file security on NTFS files and folders using the CLI
Create an NTFS security descriptor
Add NTFS DACL access control entries to the NTFS security descriptor
Add a task to the security policy
Configure and apply audit policies to NTFS files and folders using the CLI
Create an NTFS security descriptor
Add NTFS SACL access control entries to the NTFS security descriptor
Add a task to the security policy
Considerations when managing security policy jobs
Commands for managing NTFS security descriptors
Commands for managing NTFS DACL access control entries
Commands for managing NTFS SACL access control entries
Commands for managing security policies
Configure the metadata cache for SMB shares
Deploy SMB client-based services
Use offline files to allow caching of files for offline use
Requirements for using offline files
Guidelines for deploying offline files
Configure offline files support on SMB shares using the CLI
Configure offline files support on SMB shares by using the Computer Management MMC
Use roaming profiles to store user profiles centrally on a SMB server associated with the SVM
Use folder redirection to store data on a SMB server
Access the ~snapshot directory from Windows clients using SMB 2.x
Recover files and folders using Previous Versions
Requirements for using Microsoft Previous Versions
Use the Previous Versions tab to view and manage Snapshot copy data
Determine whether Snapshot copies are available for Previous Versions use
Create a Snapshot configuration to enable Previous Versions access
Deploy SMB server-based services
Manage home directories
How ONTAP enables dynamic home directories
Home directory shares
Home directory shares require unique user names
What happens to static home directory share names after upgrading
Add a home directory search path
Create a home directory configuration using the %w and %d variables
Configure home directories using the %u variable
Additional home directory configurations
Commands for managing search paths
Configure SMB client access to UNIX symbolic links
How ONTAP enables you to provide SMB client access to UNIX symbolic links
Limits when configuring UNIX symbolic links for SMB access
Control automatic DFS advertisements in ONTAP with a CIFS server option
Configure UNIX symbolic link support on SMB shares
Use BranchCache to cache SMB share content at a branch office
Requirements and guidelines
Network protocol support requirements
ONTAP and Windows hosts version requirements
Reasons ONTAP invalidates BranchCache hashes
Configure BranchCache
Requirements for configuring BranchCache
Configure BranchCache on the SMB server
Where to find information about configuring BranchCache at the remote office
Configure BranchCache-enabled SMB shares
Manage and monitor the BranchCache configuration
Modify BranchCache configurations
Display information about BranchCache configurations
Change the BranchCache server key
Pre-computing BranchCache hashes on specified paths
Flush hashes from the SVM BranchCache hash store
Display BranchCache statistics
Disable BranchCache on SMB shares
Disable or enable BranchCache on the SVM
What happens when you disable or reenable BranchCache on the CIFS server
Delete the BranchCache configuration on SVMs
Improve Microsoft remote copy performance
Improve client response time by providing SMB automatic node referrals with Auto Location
Requirements and guidelines for using automatic node referrals
Support for SMB automatic node referrals
Enable or disable SMB automatic node referrals
Use statistics to monitor automatic node referral activity
Monitor client-side SMB automatic node referral information using a Windows client
Provide folder security on shares with access-based enumeration
Enable or disable access-based enumeration on SMB shares
Enable or disable access-based enumeration from a Windows client
NFS and SMB file and directory naming dependencies
Characters a file or directory name can use
Case-sensitivity of file and directory names in a multiprotocol environment
How ONTAP creates file and directory names
How ONTAP handles multi-byte file, directory, and qtree names
Configure character mapping for SMB file name translation on volumes
Commands for managing character mappings for SMB file name translation
Provide S3 client access to NAS data
SMB configuration for Microsoft Hyper-V and SQL Server
Configure ONTAP for Microsoft Hyper-V and SQL Server over SMB solutions
Nondisruptive operations for Hyper-V and SQL Server over SMB
What are nondisruptive operations?
Protocols that enable nondisruptive operations over SMB
Key concepts about nondisruptive operations for Hyper-V and SQL Server over SMB
How SMB 3.0 functionality supports nondisruptive operations over SMB shares
What the Witness protocol does to enhance transparent failover
Share-based backups with Remote VSS
Example of a directory structure used by Remote VSS
How SnapManager for Hyper-V manages Remote VSS-based backups for Hyper-V over SMB
How ODX copy offload is used with Hyper-V and SQL Server over SMB shares
Configuration requirements and considerations
ONTAP and licensing requirements
Network and data LIF requirements
SMB server and volume requirements for Hyper-V over SMB
SMB server and volume requirements for SQL Server over SMB
Continuously available share requirements and considerations for Hyper-V over SMB
Continuously available share requirements and considerations for SQL Server over SMB
Remote VSS considerations for Hyper-V over SMB configurations
ODX copy offload requirements for SQL Server and Hyper-V over SMB
Recommendations for SQL Server and Hyper-V over SMB configurations
Plan the Hyper-V or SQL Server over SMB configuration
Create ONTAP configurations for nondisruptive operations with Hyper-V and SQL Server over SMB
Verify that both Kerberos and NTLMv2 authentication are permitted (Hyper-V over SMB shares)
Verify that domain accounts map to the default UNIX user
Verify that the security style of the SVM root volume is set to NTFS
Verify that required CIFS server options are configured
Configure SMB Multichannel for performance and redundancy
Create continuously available SMB shares
Add the SeSecurityPrivilege privilege to the user account (for SQL Server of SMB shares)
Configure the VSS shadow copy directory depth (for Hyper-V over SMB shares)
Manage Hyper-V and SQL Server over SMB configurations
Configure existing shares for continuous availability
Enable or disable VSS shadow copies for Hyper-V over SMB backups
Use statistics to monitor Hyper-V and SQL Server over SMB activity
Determine which statistics objects and counters are available
Verify that the configuration is capable of nondisruptive operations
Use health monitoring to determine whether nondisruptive operation status is healthy
Display nondisruptive operation status by using system health monitoring
Verify the continuously available SMB share configuration
Determine whether SMB sessions are continuously available
SAN storage management
SAN concepts
About SAN volumes
Configure volume provisioning options
SAN volume configuration options
About host-side space management
Automatic host-side space management with SCSI thinly provisioned LUNs
Enable space allocation for SCSI thinly provisioned LUNs
Example of how igroups give LUN access
Specify initiator WWPNs and iSCSI node names for an igroup
Storage virtualization with VMware and Microsoft copy offload
How LUN access works in a virtualized environment
Considerations for LIFs in cluster SAN environments
SAN administration
NVMe provisioning
Manage LUNs
Convert a LUN into a namespace
What to know before copying LUNs
Examine configured and used space of a LUN
Control and monitor I/O performance to LUNs using Storage QoS
Tools available to effectively monitor your LUNs
Capabilities and restrictions of transitioned LUNs
I/O misalignments on properly aligned LUNs
Manage igroups and portsets
Ways to limit LUN access with portsets and igroups
Manage iSCSI protocol
Configure your network for best performance
Define a security policy method for an initiator
Delete an iSCSI service for an SVM
Get more details in iSCSI session error recoveries
Register the SVM with an iSNS server
Manage FC protocol
Manage NVMe protocol
Start the NVMe/FC service for an SVM
Delete NVMe/FC service from an SVM
Convert a namespace into a LUN
Manage automated host discovery for NVMe/TCP
Manage systems with FC adapters
Commands for managing FC adapters
Manage LIFs for all SAN protocols
What to know before moving a SAN LIF
Remove a SAN LIF from a port set
Delete a LIF in a SAN environment
SAN LIF requirements for adding nodes to a cluster
Configure iSCSI LIFs to return FQDN to host iSCSI SendTargets Discovery Operation
Recommended volume and file or LUN configuration combinations
Determine the correct volume and LUN configuration combination for your environment
Calculate rate of data growth for LUNs
Configuration settings for space-reserved files or LUNs with thick-provisioned volumes
Configuration settings for non-space-reserved files or LUNs with thin-provisioned volumes
Configuration settings for space-reserved files or LUNs with semi-thick volume provisioning
SAN data protection
Effect of moving or copying a LUN on Snapshot copies
Restore a single LUN from a Snapshot copy
Use FlexClone LUNs to protect your data
Reasons for using FlexClone LUNs
How a FlexVol volume can reclaim free space with autodelete setting
Configure a FlexVol volume to automatically delete FlexClone files and FlexClone LUNs
Clone LUNs from an active volume
Create FlexClone LUNs from a Snapshot copy in a volume
Prevent a specific FlexClone file or FlexClone LUN from being automatically deleted
Configure and use SnapVault backups in a SAN environment
Access a read-only LUN copy from a SnapVault backup
How you can connect a host backup system to the primary storage system
SAN configuration reference
Considerations for iSCSI configurations
Considerations for FC-NVMe configurations
Considerations for FC configurations
Ways to configure FC & FC-NVMe SAN hosts with HA pairs
FC switch configuration best practices
Supported number of FC hop counts
Manage systems with FC adapters
Commands for managing FC adapters
Configure FC adapters for initiator mode
Configure FC adapters for target mode
Fibre Channel and FCoE zoning
Requirements for shared SAN configurations
Host support for multipathing
Configuration limits
Determine the number of supported nodes for SAN configurations
Determine the number of supported hosts per cluster in FC and FC-NVMe configurations
Determine the supported number of hosts in iSCSI configurations
Considerations for SAN configurations in a MetroCluster environment
S3 object storage management
S3 configuration
S3 support in ONTAP 9
ONTAP S3 architecture and use cases
About the S3 configuration process
Assess physical storage requirements
Configure S3 access to an SVM
Create and install a CA certificate on the SVM
Create an S3 service data policy
Add storage capacity to an S3-enabled SVM
Create a bucket lifecycle rule
Regenerate keys and modify their retention period
Create or modify access policy statements
About bucket and object store server policies
Create or modify an object store server policy
Enable client access to S3 object storage
Enable ONTAP S3 access for remote FabricPool tiering
Protect buckets with S3 SnapMirror
Mirror and backup protection on a remote cluster
Mirror and backup protection on the local cluster
Backup protection with cloud targets
Requirements for cloud targets
Security and data encryption
Security with ONTAP System Manager
Manage administrator authentication and RBAC
Create login accounts
Enable local account access
Enable password account access
Enable SSH public key accounts
Enable multifactor authentication (MFA) accounts
Manage multifactor authentication with ONTAP System Manager
Manage access-control roles
Modify the role assigned to an administrator
Predefined roles for cluster administrators
Manage administrator accounts
Associate a public key with an administrator account
Manage SSH public keys and X.509 certificates for an administrator account
Configure Cisco Duo 2FA for SSH logins
Generate and install a CA-signed server certificate
Manage certificates with ONTAP System Manager
Configure Active Directory domain controller access
Configure LDAP or NIS server access
Change an administrator password
Lock and unlock an administrator account
Enforce SHA-2 on administrator account passwords
Diagnose and correct file access issues with ONTAP System Manager
Authentication and authorization using OAuth 2.0
Protect against ransomware
Protect against viruses
About antivirus protection
Vscan server installation and configuration
Configure scanner pools
Create a scanner pool on a single cluster
Create scanner pools in MetroCluster configurations
Apply a scanner policy on a single cluster
Configure on-access scanning
Configure on-demand scanning
Best practices for configuring off-box antivirus functionality
Enable virus scanning on an SVM
Reset the status of scanned files
View Vscan event log information
Troubleshoot connectivity issues and monitor performance activities
Potential connectivity issues involving the scan-mandatory option
Commands for viewing Vscan server connection status
Audit NAS events on SVMs
Auditing requirements and considerations
Limitations for the size of audit records on staging files
What the supported audit event log formats are
SMB events that can be audited
Determine what the complete path to the audited object is
NFS file and directory access events that can be audited
Plan the auditing configuration
Create a file and directory auditing configuration on SVMs
Configure file and folder audit policies
Configure audit policies on NTFS security-style files and directories
Configure auditing for UNIX security style files and directories
Display information about audit policies applied to files and directories
Display information about audit policies using the Windows Security tab
Display information about NTFS audit policies on FlexVol volumes using the CLI
Ways to display information about file security and audit policies
CLI change events that can be audited
Use FPolicy for file monitoring and management on SVMs
Understand FPolicy
What the two parts of the FPolicy solution are
What synchronous and asynchronous notifications are
Roles that cluster components play with FPolicy implementation
How FPolicy works with external FPolicy servers
What the node-to-external FPolicy server communication process is
How FPolicy services work across SVM namespaces
How FPolicy passthrough-read enhances usability for hierarchical storage management
Plan the FPolicy configuration
Requirements, considerations, and best practices for configuring FPolicy
What the steps for setting up an FPolicy configuration are
Plan the FPolicy external engine configuration
Complete the FPolicy external engine configuration worksheet
Plan the FPolicy event configuration
Supported file operation and filter combinations that FPolicy can monitor for SMB
Supported file operation and filter combinations that FPolicy can monitor for NFSv3
Supported file operation and filter combinations that FPolicy can monitor for NFSv4
Plan the FPolicy policy configuration
Requirement for FPolicy scope configurations if the FPolicy policy uses the native engine
Create the FPolicy configuration
Manage FPolicy configurations
Modify FPolicy configurations
Display information about FPolicy configurations
Commands for displaying information about FPolicy configurations
Verify access using security tracing
Types of access checks security traces monitor
Considerations when creating security traces
Perform security traces
Display information about security trace filters
Manage encryption with ONTAP System Manager
Manage encryption with the CLI
Configure Volume Encryption
Configure VE
Determine whether your cluster version supports VE
Configure external key management
Manage external keys with ONTAP System Manager
Encrypt volume data with VE
Enable aggregate-level encryption with VE license
Enable encryption on a new volume
Enable encryption on an existing volume with the volume encryption conversion start command
Enable encryption on an existing volume with the volume move start command
Configure hardware-based encryption
Configure external key management
Install SSL certificates on the cluster
Enable external key management in ONTAP 9.7 and later (HW-based)
Configure clustered external key server
Create authentication keys in ONTAP 9.7 and later
Assign a data authentication key to a FIPS drive or SED (external key management)
Configure onboard key management
Enable onboard key management in ONTAP 9.7 and later
Assign a data authentication key to a FIPS drive or SED (onboard key management)
Assign a FIPS 140-2 authentication key to a FIPS drive
Enable cluster-wide FIPS-compliant mode for KMIP server connections
Manage Fujitsu encryption
Delegate authority to run the volume move command
Change the encryption key for a volume with the volume encryption rekey start command
Rotate authentication keys for Storage Encryption
Securely purge data on an encrypted volume
Securely purge data on an encrypted volume without a SnapMirror relationship
Securely purge data on an encrypted volume with an Asynchronous SnapMirror relationship
Scrub data on an encrypted volume with a Synchronous SnapMirror relationship
Change the onboard key management passphrase
Back up onboard key management information manually
Restore onboard key management encryption keys
Restore external key management encryption keys
Make data on a FIPS drive or SED inaccessible
Return a FIPS drive or SED to service when authentication keys are lost
Return a FIPS drive or SED to unprotected mode
Remove an external key manager connection
Modify external key management server properties
Transition to external key management from onboard key management
Transition to onboard key management from external key management
What happens when key management servers are not reachable during the boot process
Data protection and disaster recovery
Data protection with ONTAP System Manager
Create custom data protection policies
Enable or disable client access to Snapshot copy directory
Prepare for mirroring and vaulting
Resynchronize a protection relationship
Restore a volume from an earlier Snapshot copy
Reverse resynchronize a protection relationship
Configure storage VM disaster recovery
Serve data from an SVM DR destination
Reactivate a source storage VM
Cluster and SVM peering with the CLI
Prepare for cluster and SVM peering
Configure intercluster LIFs
Configure intercluster LIFs on shared data ports
Configure peer relationships
Create a cluster peer relationship
Enable cluster peering encryption on an existing peer relationship
Remove cluster peering encryption from an existing peer relationship
Data protection with the CLI
Manage local Snapshot copies
Configure custom Snapshot policies
When to configure a custom Snapshot policy
Manage the Snapshot copy reserve
When to increase the Snapshot copy reserve
How deleting protected files can lead to less file space than expected
Monitor Snapshot copy disk consumption
Check available Snapshot copy reserve on a volume
SnapMirror volume replication
Asynchronous SnapMirror disaster recovery basics
SnapMirror Synchronous disaster recovery basics
About workloads supported by StrictSync and Sync policies
Vault archiving using SnapMirror technology
SnapMirror unified replication basics
XDP replaces DP as the SnapMirror default
When a destination volume grows automatically
Fan-out and cascade data protection deployments
SnapMirror licensing
Manage SnapMirror volume replication
SnapMirror replication workflow
Configure a replication relationship in one step
Configure a replication relationship one step at a time
Create a replication job schedule
Customize a replication policy
Create a custom replication policy
Define a schedule for creating a local copy on the destination
Create a replication relationship
Convert an existing DP-type relationship to XDP
Convert the type of a SnapMirror relationship
Convert the mode of a SnapMirror Synchronous relationship
Create and delete SnapMirror failover test volumes
Serve data from a SnapMirror DR destination volume
Make the destination volume writeable
Restore files from a SnapMirror destination volume
Restore a single file, LUN, or NVMe namespace from a SnapMirror destination
Restore the contents of a volume from a SnapMirror destination
Update a replication relationship manually
Resynchronize a replication relationship
About SnapMirror SVM replication
Manage SnapMirror SVM replication
Replicate SVM configurations
SnapMirror SVM replication workflow
Criteria for placing volumes on destination SVMs
Replicate an entire SVM configuration
Exclude LIFs and related network settings from SVM replication
Exclude network, name service, and other settings from SVM replication
Serve data from an SVM DR destination
Convert volume replication relationships to an SVM replication relationship
Manage SnapMirror root volume replication
Create and initializing load-sharing mirror relationships
Archive and compliance using SnapLock technology
Manage WORM files
Commit Snapshot copies to WORM on a vault destination
Mirror WORM files for disaster recovery
Consistency groups
Configure a single consistency group
Configure a hierarchical consistency group
SnapMirror Business Continuity
Manage SM-BC and protect data
Recover from automatic unplanned failover operations
Add and remove volumes in a consistency group
Troubleshoott
SnapMirror delete operation fails in takover state
Failure creating a SnapMirror relationship and initializing consistency group
Mediator not reachable or Mediator quorum status is false
Automatic unplanned failover not triggered on Site B
Link between Site B and Mediator down and Site A down
Link between Site A to Mediator Down and Site B down
SM-BC SnapMirror delete operation fails when fence is set on destination volumes
Volume move operation stuck when primary site is down
Mediator service for MetroCluster and SnapMirror Business Continuity
Install or upgrade
Manage MetroCluster sites with ONTAP System Manager
Perform MetroCluster switchover and switchback
Data protection using tape backup
Tape backup and restore workflow
Use cases for choosing a tape backup engine
Manage tape drives
Commands for managing tape drives, media changers, and tape drive operations
About tape drives
Qualified tape drives overview
Format of the tape configuration file
How the storage system qualifies a new tape drive dynamically
Tape devices overview
Considerations when configuring multipath tape access
NDMP for FlexVol volumes
About NDMP for FlexVol volumes
Considerations when using NDMP
Common NDMP tape backup topologies
Supported NDMP authentication methods
NDMP extensions supported by ONTAP
NDMP restartable backup extension for a dump supported by ONTAP
About NDMP for FlexGroup volumes
About NDMP with SnapLock volumes
Manage node-scoped NDMP mode for FlexVol volumes
Manage SVM-scoped NDMP mode for FlexVol volumes
Commands for managing SVM-scoped NDMP mode
What Cluster Aware Backup extension does
Availability of volumes and tape devices for backup and restore on different LIF types
NDMP server supports secure control connections in SVM-scoped mode
User authentication in the SVM-scoped NDMP mode
About dump engine for FlexVol volumes
Types of data that the dump engine backs up
Types of data that the dump engine restores
Considerations before restoring data
How dump works on a SnapVault secondary volume
How dump works with storage failover and ARL operations
How dump works with volume move
How dump works when a FlexVol volume is full
How dump works when volume access type changes
How dump works with SnapMirror single file or LUN restore
How dump backup and restore operations are affected in MetroCluster configurations
About SMTape engine for FlexVol volumes
Use Snapshot copies during SMTape backup
Features not supported in SMTape
Scalability limits for SMTape backup and restore sessions
How SMTape works with storage failover and ARL operations
How SMTape works with volume move
How SMTape works with volume rehost operations
How NDMP backup policy are affected during ADB
How SMTape backup and restore operations are affected in MetroCluster configurations
Monitor tape backup and restore operations for FlexVol volumes
What the dump and restore event log message format is
Error messages for tape backup and restore of FlexVol volumes
Backup and restore error messages
Resource limitation: no available thread
Maximum number of allowed dumps or restores (maximum session limit) in progress
Tape write failed - new tape encountered media error
Tape write failed - new tape is broken or write protected
Tape write failed - new tape is already at the end of media
Tape record size is too small. Try a larger size.
NDMP error messages
Message from Read Socket: error_string
Message from Write Dirnet: error_string
ndmpd invalid version number: version_number ``
ndmpd session session_ID not active
Could not obtain vol ref for Volume volume_name
DATA LISTEN: CAB data connection prepare precondition error
DATA CONNECT: CAB data connection prepare precondition error
Error:show failed: Cannot get password for user '<username>'
Dump error messages
Destination volume is read-only
Destination qtree is read-only
Dumps temporarily disabled on volume, try again
Restore of the file <file name> failed
Truncation failed for src inode <inode number>…
SMTape error messages
Failed to initialize restore stream
Image header missing or corrupted
Invalid backup image magic number
Job aborted due to Snapshot autodelete
Tape is currently in use by other operations
Transfer failed (Aborted due to MetroCluster operation)
Transfer failed (ARL initiated abort)
Transfer failed (CFO initiated abort)
Transfer failed (SFO initiated abort)
Underlying aggregate under migration
NDMP configuration
Prepare for NDMP configuration
Verify tape device connections
Configure SVM-scoped NDMP
Enable SVM-scoped NDMP on the cluster
Replication between Element software and ONTAP
Enable SnapMirror in Element software
Enable SnapMirror on the Element cluster
Configure a replication relationship
Create a replication job schedule
Create a replication relationship
Create a relationship from an Element source to an ONTAP destination
Create a relationship from an ONTAP source to an Element destination
Serve data from a SnapMirror DR destination volume
Make the destination volume writeable
Event and performance monitoring
Monitor cluster performance with ONTAP System Manager
Monitor and manage cluster performance using the CLI
Monitor performance
Verify that your VMware environment is supported
Active IQ Unified Manager worksheet
Install Active IQ Unified Manager
Manage performance issues
Perform basic infrastructure checks
Check protocol settings on the storage system
Check the NFS TCP maximum transfer size
Check the iSCSI TCP read/write size
Check the network settings on the data switches
Check the MTU network setting on the storage system
Manage workloads
Monitor cluster performance with Unified Manager
EMS configuration
Configure EMS event notifications with ONTAP System Manager
Configure EMS event notifications with the CLI
Configure EMS events to send email notifications
Configure EMS events to forward notifications to a syslog server
Configure SNMP traphosts to receive event notifications
Configure EMS events to forward notifications to a webhook application
Update deprecated EMS event mapping
Key concepts
SnapMirror Business Continuity (SM-BC) utilizes features such as consistency groups and the ONTAP Mediator to ensure your data is replicated and served even in the event of a disaster scenario. When planning your SM-BC deployment, it is important to understand the essential concepts in SM-BC and its architecture.
Architecture
The following figure illustrates a high-level overview of an SM-BC deployment.
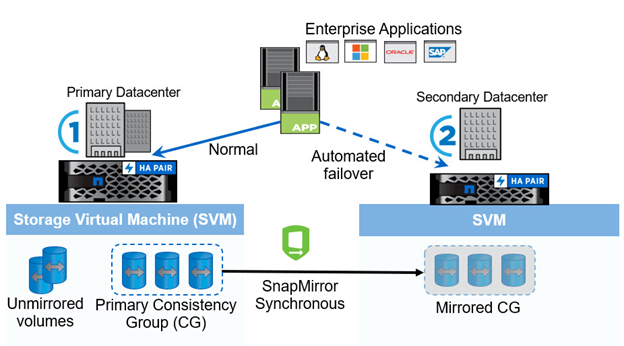
The diagram shows an enterprise application that is hosted on an storage VM (SVM) at the primary data center. The SVM contains five volumes, three of which are part of a consistency group. The three volumes in the consistency group are mirrored to a secondary data center. In normal circumstances, all write operations are performed to the primary data center; in effect, this data center serves as the source for I/O operations, while the secondary data center serves as a destination.
In the event of a disaster scenario at the primary data center, the ONTAP Mediator will direct the secondary data center to act as the primary, serving all I/O operations. Only the volumes that are mirrored in the consistency group will be served. Any operations pertaining to the other two volumes on the SVM will be affected by the disaster event.
Essential concepts
Understanding the following terms will help you deploy SM-BC.
A consistency group is a collection of volumes or LUNs that provide a write-order consistency guarantee for the application workload that needs to be protected for business continuity. A consistency group ensures all volumes of this data set are quiesced and then snapped at the same point in time, providing a data-consistent restore point across volumes for that data set.
In SM-BC, you will create a primary and secondary consistency group for replication and data protection. The secondary consistency group will serve your data in the event of a disruption.
To learn more about consistency groups, see Consistency groups overview.
An individual volume or LUN that is part of a consistency group, which is protected by the SM-BC relationship.
The ONTAP Mediators monitors the two ONTAP clusters and orchestrates failover in case your primary storage system fails. With the ONTAP Mediator, your application automatically reconnects to the resources in the secondary storage system.
With the ONTAP Mediator’s health information, clusters can differentiate between intercluster LIF failure and site failure. When the site goes down, ONTAP Mediator passes on the health information to the peer cluster on demand, facilitating the peer cluster to failover.
Learn more about the ONTAP Mediator.
A manual operation to change the roles of copies in a SM-BC relationship. The primary sites becomes the secondary, and the secondary becomes the primary.
An automatic operation to perform a failover to the mirror copy. The operation requires assistance from Mediator to detect that the primary copy is unavailable.
When the application I/O is not replicating to the secondary storage system, it will be reported as out of sync. An out of sync status means the secondary volumes are not synchronized with the primary (source) and that SnapMirror replication is not occurring.
If the mirror state is Snapmirrored, this indicates a transfer failure or failure due to an unsupported operation.
RPO stands for recovery point objective, which is the amount of data loss deemed acceptable during a given time period. Zero RPO signifies that no data loss is acceptable.
RTO stands for recovery time objective, which is the amount of time that is deemed acceptable for an application to return to normal operations following an outage, failure, or other data loss event. Zero RTO signifies that no amount of downtime is acceptable.