
![]()
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
ONTAP 9 マニュアル ( CA08871-402 )
CLIを使用した4ノードまたは8ノードMetroCluster構成の手動無停止ONTAPアップグレード
4ノードまたは8ノードMetroCluster構成の手動アップグレードでは、更新の準備を行い、1つまたは2つのDRグループの各DRペアを同時に更新し、アップグレード後の手順を実行します。
-
2ノードMetroCluster構成では、この手順を使用しないでください。
-
ここで説明する手順では、ONTAPの古いバージョンと新しいバージョンという表現を使用します。
-
アップグレード手順での古いバージョンとは、ONTAPの以前のバージョン、つまりONTAPの新しいバージョンよりもバージョン番号が低いバージョンを指します。
-
ダウングレード手順での古いバージョンとは、ONTAPのあとのバージョン、つまりONTAPの新しいバージョンよりもバージョン番号が高いバージョンを指します。
-
-
この手順のワークフローは次のとおりです。
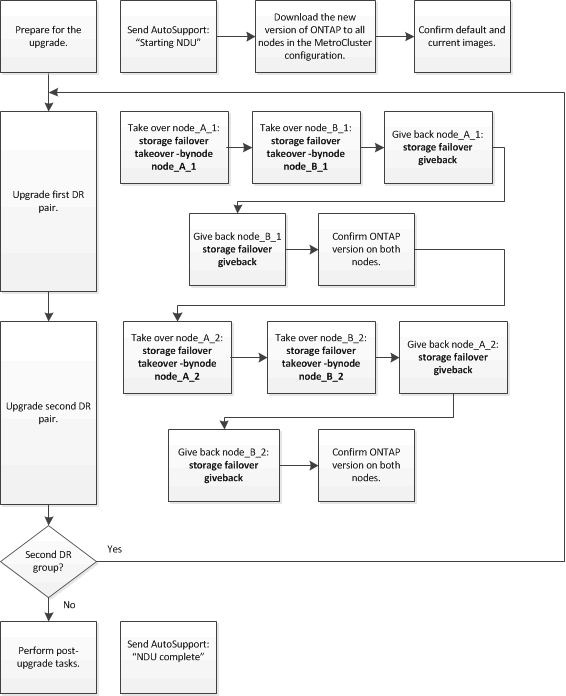
ONTAPソフトウェアを8ノードと4ノードのMetroCluster構成でアップデートする際の相違点
MetroClusterソフトウェアのアップグレード プロセスは、MetroClusterが8ノード構成か4ノード構成かによって異なります。
1つのMetroCluster構成は、1つまたは2つのDRグループで構成されます。個々のDRグループは、2つのHAペアで構成されます(それぞれのMetroClusterクラスタに1つのHAペア)。8ノードのMetroClusterには、2つのDRグループが含まれています。
DRグループを一度に1つずつアップグレードします。
-
DRグループ1をアップグレードします。
-
node_A_1とnode_B_1をアップグレードします。
-
node_A_2とnode_B_2をアップグレードします。
-
-
DRグループ1をアップグレードします。
-
node_A_1とnode_B_1をアップグレードします。
-
node_A_2とnode_B_2をアップグレードします。
-
-
DRグループ2をアップグレードします。
-
node_A_3とnode_B_3をアップグレードします。
-
node_A_4とnode_B_4をアップグレードします。
-
MetroCluster DRグループのアップグレード準備
ノード上のONTAPソフトウェアをアップグレードする前に、ノード間のDR関係を特定して、アップグレードを開始することを知らせるAutoSupportメッセージを送信します。また、各ノードで実行中のONTAPのバージョンを確認します。
以下の手順は、DRグループごとに繰り返す必要があります。MetroCluster構成が8つのノードで構成されている場合は、DRグループが2つあります。そのため、両方のDRグループでこの手順を行う必要があります。
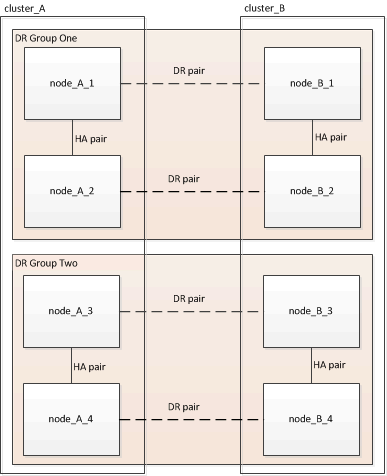
この手順の例では、次の図に示すクラスタとノードの名前を使用しています。
-
構成内のDRペアを特定します。
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
権限レベルをadminからadvancedに変更します。続行するかを尋ねられたら、「y」と入力します。
set -privilege advancedadvancedのプロンプト(
*>)が表示されます。 -
cluster_AのONTAPのバージョンを確認します。
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_BのONTAPのバージョンを確認します。
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
AutoSupport通知を送信します。
autosupport invoke -node * -type all -message "Starting_NDU"このAutoSupport通知には、アップグレード前のシステム ステータスの記録が含まれます。これにより、アップグレード処理で問題が発生した場合に役立つトラブルシューティング情報が保存されます。
AutoSupportメッセージを送信するようにクラスタが設定されていない場合は、通知のコピーがローカルに保存されます。
-
最初のセットに含まれる各ノードについて、ターゲットのONTAPソフトウェア イメージをデフォルトのイメージとして設定します。
system image modify {-node nodename -iscurrent false} -isdefault trueこのコマンドは、拡張クエリを使用して、代替イメージとしてインストールされるターゲットのソフトウェア イメージがノードのデフォルトのイメージになるように変更します。
-
ターゲットのONTAPソフトウェア イメージがcluster_Aでデフォルトのイメージとして設定されたことを確認します。
system image show次の例では、image2が新しいONTAPバージョンで、最初のセットに含まれる各ノードでデフォルトのイメージとして設定されています。
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
ターゲットのONTAPソフトウェア イメージがcluster_Bでデフォルトのイメージとして設定されたことを確認します。
system image show次の例では、最初のセットに含まれる各ノードで、ターゲットのバージョンがデフォルトのイメージとして設定されています。
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.
-
-
各ノードに対して次のコマンドを2回実行して、アップグレード対象のノードが現在クライアントに対して処理を行っているかを確認します。
system node run -node target-node -command uptimeuptimeコマンドでは、ノードの前回のブート以降にNFS、CIFS、FC、iSCSIの各クライアントに対してノードが実行した処理の総数が表示されます。各プロトコルについてコマンドを2回実行して、処理数が増加しているかを確認する必要があります。増加している場合は、そのプロトコルのクライアントに対してノードが現在処理を行っています。増加していない場合は、そのプロトコルのクライアントに対してノードは現在処理を行っていません。
ノードのアップグレード後にクライアント トラフィックが再開したことを確認できるように、クライアントの処理数が増加している各プロトコルを書き留めておいてください。 次の例は、NFS、CIFS、FC、およびiSCSIの処理が含まれるノードを示しています。ただし、ノードは現在NFSクライアントとiSCSIクライアントに対してのみ処理を行っています。
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
MetroCluster DRグループ内の最初のDRペアの更新
ONTAPの新しいバージョンをノードの現在のバージョンにするには、ノードのテイクオーバーとギブバックを適切な順序で行う必要があります。
すべてのノードで古いバージョンのONTAPを実行する必要があります。
この手順では、node_A_1とnode_B_1をアップグレードします。
最初のDRグループのONTAPソフトウェアをアップグレード済みで、8ノードMetroCluster構成内の2つ目のDRグループをアップグレードする場合は、この手順でnode_A_3とnode_B_3を更新します。
-
MetroCluster Tiebreakerソフトウェアが有効になっている場合は、無効にします。
-
HAペアの各ノードで自動ギブバックを無効にします。
storage failover modify -node target-node -auto-giveback falseこのコマンドはHAペアのノードごとに実行する必要があります。
-
自動ギブバックが無効になっていることを確認します。
storage failover show -fields auto-giveback次の例は、両方のノードで自動ギブバックが無効になっていることを示しています。
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
各コントローラーのI/Oが約50%未満であることと、CPU利用率がコントローラーあたり約50%未満であることを確認します。
-
cluster_Aのターゲット ノードのテイクオーバーを開始します。
テイクオーバーするノードを新しいソフトウェア イメージでブートするには通常のテイクオーバーが必要なため、-option immediateパラメーターは指定しないでください。
-
cluster_A(node_A_1)のDRパートナーをテイクオーバーします。
storage failover takeover -ofnode node_A_1ノードがブートし、「Waiting for giveback」状態になります。
AutoSupportが有効な場合は、ノードがクラスタ クォーラムのメンバーでないことを示すAutoSupportメッセージが送信されます。この通知を無視し、アップグレードを続行してかまいません。 -
テイクオーバーが正常に完了したことを確認します。
storage failover show次の例は、テイクオーバーが正常に完了したことを示しています。node_A_1の状態は「Waiting for giveback」、node_A_2の状態は「In takeover」になっています。
cluster1::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed.
-
-
cluster_B(node_B_1)のDRパートナーをテイクオーバーします。
テイクオーバーするノードを新しいソフトウェア イメージでブートするには通常のテイクオーバーが必要なため、-option immediateパラメーターは指定しないでください。
-
node_B_1をテイクオーバーします。
storage failover takeover -ofnode node_B_1ノードがブートし、「Waiting for giveback」状態になります。
AutoSupportが有効な場合は、ノードがクラスタ クォーラムのメンバーでないことを示すAutoSupportメッセージが送信されます。この通知を無視し、アップグレードを続行してかまいません。 -
テイクオーバーが正常に完了したことを確認します。
storage failover show次の例は、テイクオーバーが正常に完了したことを示しています。node_B_1の状態は「Waiting for giveback」、node_B_2の状態は「In takeover」になっています。
cluster1::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed.
-
-
8分以上待ってから、次の条件を満たしていることを確認します。
-
クライアントのマルチパス(導入している場合)が安定している。
-
クライアントがテイクオーバー中に発生したI/Oの中断から回復している。
回復までの時間はクライアントによって異なり、クライアント アプリケーションの特性によっては8分以上かかることもあります。
-
-
アグリゲートをターゲット ノードに戻します。
MetroCluster IP構成をONTAP 9.7以降にアップグレードすると、アグリゲートの状態は短時間degradedになったあとに再同期されてmirroredに戻ります。
-
アグリゲートをcluster_AのDRパートナーにギブバックします。
storage failover giveback –ofnode node_A_1 -
アグリゲートをcluster_BのDRパートナーにギブバックします。
storage failover giveback –ofnode node_B_1ギブバック処理では、最初にルート アグリゲートがノードに戻され、そのノードのブートが完了するとルート以外のアグリゲートが戻されます。
-
-
両方のクラスタで次のコマンドを実行して、すべてのアグリゲートが戻されたことを確認します。
storage failover show-givebackGiveback Statusフィールドにギブバックするアグリゲートがないことが示されている場合は、すべてのアグリゲートが戻されています。ギブバックが拒否された場合は、コマンドによってギブバックの進捗が表示され、拒否したサブシステムも表示されます。
-
戻されていないアグリゲートがある場合は、次の操作を実行します。
-
拒否の対処方法を確認して、「
拒否」状態に対処するか、拒否を無視するかを指定します。 -
必要に応じて、エラー メッセージに示された「
拒否」状態に対処して、特定された処理が正常に終了するようにします。 -
storage failover givebackコマンドを再度入力します。
「
拒否」状態を無視する場合は、-override-vetoesパラメーターをtrueに設定します。
-
-
8分以上待ってから、次の条件を満たしていることを確認します。
-
クライアントのマルチパス(導入している場合)が安定している。
-
クライアントがギブバック中に発生したI/Oの中断から回復している。
回復までの時間はクライアントによって異なり、クライアント アプリケーションの特性によっては8分以上かかることもあります。
-
-
権限レベルをadminからadvancedに変更します。続行するかを尋ねられたら、「y」と入力します。
set -privilege advancedadvancedのプロンプト(
*>)が表示されます。 -
cluster_AのONTAPのバージョンを確認します。
system image show次の例は、System image2がnode_A_1のデフォルトおよび現在のバージョンであることを示しています。
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_BのONTAPのバージョンを確認します。
system image show次の例は、System image2がnode_A_1のデフォルトおよび現在のバージョンであることを示しています。
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::>
MetroCluster DRグループ内の2つ目のDRペアの更新
ONTAPの新しいバージョンをノードの現在のバージョンにするには、ノードのテイクオーバーとギブバックを正しい順番で行う必要があります。
最初のDRペア(node_A_1とnode_B_1)をアップグレードしておく必要があります。
この手順では、node_A_2とnode_B_2をアップグレードします。
最初のDRグループのONTAPソフトウェアをアップグレード済みで、8ノードMetroCluster構成内の2つ目のDRグループを更新する場合は、この手順でnode_A_4とnode_B_4を更新します。
-
ノードからすべてのデータLIFを移行します。
network interface migrate-all -node nodenameA -
cluster_Aのターゲット ノードのテイクオーバーを開始します。
テイクオーバーするノードを新しいソフトウェア イメージでブートするには通常のテイクオーバーが必要なため、-option immediateパラメーターは指定しないでください。
-
cluster_AのDRパートナーをテイクオーバーします。
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch -
テイクオーバーが正常に完了したことを確認します。
storage failover show次の例は、テイクオーバーが正常に完了したことを示しています。node_A_2の状態は「Waiting for giveback」、node_A_1の状態は「In takeover」になっています。
cluster1::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed.
-
-
cluster_Bのターゲット ノードのテイクオーバーを開始します。
テイクオーバーするノードを新しいソフトウェア イメージでブートするには通常のテイクオーバーが必要なため、-option immediateパラメーターは指定しないでください。
-
cluster_B(node_B_2)のDRパートナーをテイクオーバーします。
-
テイクオーバーが正常に完了したことを確認します。
storage failover show次の例は、テイクオーバーが正常に完了したことを示しています。node_B_2の状態は「Waiting for giveback」、node_B_1の状態は「In takeover」になっています。
cluster1::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed.
-
-
8分以上待ってから、次の条件を満たしていることを確認します。
-
クライアントのマルチパス(導入している場合)が安定している。
-
クライアントがテイクオーバー中に発生したI/Oの中断から回復している。
回復までの時間はクライアントによって異なり、クライアント アプリケーションの特性によっては8分以上かかることもあります。
-
-
アグリゲートをターゲット ノードに戻します。
-
アグリゲートをcluster_AのDRパートナーにギブバックします。
storage failover giveback –ofnode node_A_2 -
アグリゲートをcluster_BのDRパートナーにギブバックします。
storage failover giveback –ofnode node_B_2ギブバック処理では、最初にルート アグリゲートがノードに戻され、そのノードのブートが完了するとルート以外のアグリゲートが戻されます。
-
-
両方のクラスタで次のコマンドを実行して、すべてのアグリゲートが戻されたことを確認します。
storage failover show-givebackGiveback Statusフィールドにギブバックするアグリゲートがないことが示されている場合は、すべてのアグリゲートが戻されています。ギブバックが拒否された場合は、コマンドによってギブバックの進捗が表示され、拒否したサブシステムも表示されます。
-
戻されていないアグリゲートがある場合は、次の操作を実行します。
-
拒否の対処方法を確認して、「
拒否」状態に対処するか、拒否を無視するかを指定します。 -
必要に応じて、エラー メッセージに示された「
拒否」状態に対処して、特定された処理が正常に終了するようにします。 -
storage failover givebackコマンドを再度入力します。
「
拒否」状態を無視する場合は、-override-vetoesパラメーターをtrueに設定します。
-
-
8分以上待ってから、次の条件を満たしていることを確認します。
-
クライアントのマルチパス(導入している場合)が安定している。
-
クライアントがギブバック中に発生したI/Oの中断から回復している。
回復までの時間はクライアントによって異なり、クライアント アプリケーションの特性によっては8分以上かかることもあります。
-
-
権限レベルをadminからadvancedに変更します。続行するかを尋ねられたら、「y」と入力します。
set -privilege advancedadvancedのプロンプト(
*>)が表示されます。 -
cluster_AのONTAPのバージョンを確認します。
system image show次の例は、System image2(ターゲットのONTAPイメージ)がnode_A_2のデフォルトおよび現在のバージョンであることを示しています。
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_BのONTAPのバージョンを確認します。
system image show次の例は、System image2(ターゲットのONTAPイメージ)がnode_B_2のデフォルトおよび現在のバージョンであることを示しています。
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
HAペアの各ノードで自動ギブバックを有効にします。
storage failover modify -node target-node -auto-giveback trueこのコマンドはHAペアのノードごとに実行する必要があります。
-
自動ギブバックが有効になっていることを確認します。
storage failover show -fields auto-giveback次の例は、両方のノードで自動ギブバックが有効になっていることを示しています。
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.